
从图集合中剔除同构
我有一个15M (百万) DAGs (有向无圈图,实际上是有向超立方体)的集合,我想从其中删除同构。这方面的常见算法是什么?每个图都相当小,一个维数N的超立方体,其中N为3到6(目前),因此在N=6情况下,每个图都有64个节点。
通过使用networkx和python,我这样实现了它,它适用于300 k(1000)这样的小集合(几天内运行)。
def isIsomorphicDuplicate(hcL, hc):
"""checks if hc is an isomorphism of any of the hc's in hcL
Returns True if hcL contains an isomorphism of hc
Returns False if it is not found"""
#for each cube in hcL, check if hc could be isomorphic
#if it could be isomorphic, then check if it is
#if it is isomorphic, then return True
#if all comparisons have been made already, then it is not an isomorphism and return False
for saved_hc in hcL:
if nx.faster_could_be_isomorphic(saved_hc, hc):
if nx.fast_could_be_isomorphic(saved_hc, hc):
if nx.is_isomorphic(saved_hc, hc):
return True
return False一个更好的方法是将每个图转换为它的规范排序,对集合进行排序,然后删除重复的集合。这绕过了检查二进制is_isomophic()测试中的15M图,我相信上面的实现类似于O(N!N) (不考虑同构时间),而对于转换+ O(log(N)N)来删除重复项,一个干净的将所有图转换为规范序和排序的转换应该采用O(N)表示。O(N!N) >> O(log(N)N)
我发现这篇论文是关于正则图标号的,但它用数学方程描述得非常简洁,没有伪码:“McKay的正则图标号算法”-- http://www.math.unl.edu/~aradcliffe1/Papers/Canonical.pdf
tldr:我有一个不可能的大量图要通过二进制同构检查来检查。我相信这通常是通过规范排序来完成的。是否存在任何打包算法或公开发布的直接实现算法(即有伪代码)?
回答 6
Stack Overflow用户
发布于 2014-11-18 18:11:21
以下是哈特克和拉德克利夫·哈特克( McKay )和拉德克利夫( Radcliffe [链接到纸张] )提出的标准图标记算法的分解。
首先,我应该指出,在这里有一个开源实现:nauty和Traces源代码。
好吧,我们开始吧!不幸的是,这种算法在图论中很难实现,所以我们需要一些术语。首先,我将从定义同构和自变体开始。
同构:
如果两个图是相同的,则它们是同构的,但顶点的标号是不同的。以下两个图是同构的。
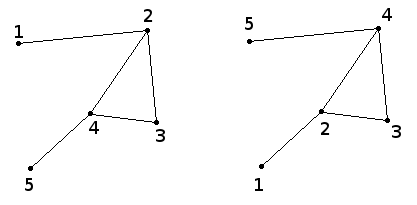
Automorphic:
如果两个图是完全相同的,则它们是自同构的,包括顶点标号。以下两个图是自同构的。这似乎微不足道,但由于技术原因,这是很重要的。
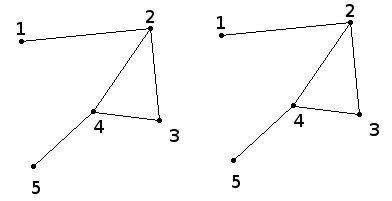
图散列:
整个过程的核心思想是有一种方法将一个图散列成一个字符串,然后对一个给定的图计算所有与它同构的图的哈希字符串。按字母顺序(从技术上来说)最大的同构散列字符串称为“规范散列”,生成它的图形称为“规范同构”或“规范标记”。
这样,要检查任何两个图是否是同构的,只需检查它们的规范同构(或规范标签)是否相等(即彼此的自同构)。哇行话!不幸的是,如果没有行话,这就更令人困惑了:
对于图G,我们将要使用的散列函数称为i(G):通过查看G中的每一对顶点(按顶点标号的顺序)构建二进制字符串,如果这两个顶点之间有一条边,则放一个"1“,如果没有,则为"0”。这样,i(G)中的j位表示图中没有该边的存在。
McKay的正则图标记算法
问题是,对于n个顶点上的图,有O( n!)可能的同构散列字符串是基于如何标记顶点的,如果我们必须多次计算相同的字符串(即自同构),则可能会有更多的同构散列。通常,我们必须计算每一个同形散列,才能找到最大的一个,没有神奇的排序切割。McKay算法是一种搜索算法,它通过将所有的自同构从搜索树中剪除,从而更快地找到这个标准的等深线,迫使正则等深线中的顶点按增加的度顺序被标记,还有一些其他的技巧可以减少我们必须散列的同构数。
(1)第4节:McKay的第一步是根据度对顶点进行排序,将大部分的等深线剔除,但不一定是唯一的排序,因为给定度可能有多个顶点。例如,下面的图有6个顶点,顶点{ 1,2, 3 }有1次,verts {4,5}有度2,而vert {6}有3次,它根据顶点度的偏序是{1,2,3,4,5,5}。
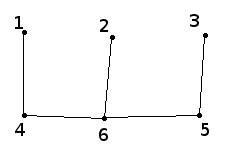
(2)第5节:在顶点度不区分的顶点上施加人工对称,基本上取同一阶的一个顶点群,然后依次取一个顶点作为全序的第一位(图1)。在本文中,因此在我们的示例中,节点{1,2,3,4,5}通过扩展组{1,2,3}和扩展组{4,5}具有子节点{ {1|2,3|4,5|6},{2|1,3|4,5|6}},{3|1,2|4,5|6}} }。这种分裂可以一直持续到叶节点,这些节点都是完全有序的,如{1\2\6},它描述了G的完全等形,这使我们能够从(1),{1,2,3,4,5,5}中取顶点度的偏序,并建立一棵树,列出所有标准等形的候选对象--这已经比n更少了!组合,因为,例如,顶点6将永远不会第一。请注意,McKay以深度优先的方式评估子级,首先从最小的组开始,这将导致一个更深但更窄的树,这对下一步的在线剪枝更好。还请注意,每个总排序叶节点可能出现在多个子树中,这就是剪枝出现的地方!
(3)第6节:在搜索树时,寻找自同构,并利用它修剪树。这里的数学有点高于我,但是我认为如果你发现树上的两个节点是彼此的自同构,那么你可以安全地修剪它们的一个子树,因为你知道它们都会产生相同的叶节点。
我只给出了麦凯的高级描述,论文深入到了数学的更深层次,构建一个实现需要对这个数学有一定的理解。希望我已经给您提供了足够的上下文,可以让您回过头来重新阅读报纸,或者阅读实现的源代码。
Stack Overflow用户
发布于 2014-11-13 02:24:15
这是一个有趣的问题,我没有答案!这是我的两分钱
15M是指1500万无向图吗?每一个有多大?是否有已知的属性(树木,planar,k-trees)?
你试过通过预先检测假阳性来减少检查的次数吗?包括计算和比较数字,如顶点,边度和度序列?除了其他试探法外,还要测试给定的两个图是否不是同构的。另外,检查小淘气。这可能是您检查它们(并生成规范排序)的方法。
Stack Overflow用户
发布于 2014-11-17 19:55:39
这的确是一个有趣的问题。
我会从邻接矩阵的角度来处理它。两个同构图将有邻接矩阵,其中行/列的顺序不同。因此,我的想法是为每个图计算几个矩阵属性,这些属性对于行/列交换是不变的,从我的头顶开始:
numVerts, min, max, sum/mean, trace (probably not useful if there are no reflexive edges), norm, rank, min/max/mean column/row sums, min/max/mean column/row norm
任意一对同构图在所有性质上都是相同的。
您可以创建一个哈希函数,它接收一个图形,并发出一个哈希字符串,如
string hashstr = str(numVerts)+str(min)+str(max)+str(sum)+...然后根据哈希字符串对所有图进行排序,您只需要对散列相同的图进行完全同构检查。
假设你在36个节点上有1500万个图,我假设你是在处理加权图,对于没有加权的无向图,这个技巧就不那么有效了。
https://stackoverflow.com/questions/26893304
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号