
支持向量机作为一种基于实例的学习方式?
我读了很多关于支持向量机的文章,在我看到的所有书籍和在线文章中,支持向量机被归类为使用超平面的线性分类器。如果数据不能线性可分,则可以将数据映射到高维,以启用线性边界。
现在,我看到了华盛顿大学著名机器学习专家佩德罗·多明戈斯教授的一些文章和幻灯片。他特别将支持向量机归类为一种基于实例的机器学习算法,类似于kNN.有人能跟我解释一下吗?
例如,在文章 in Communications of the ACM (2012年10月)中,他特别将支持向量机置于“实例”-based表示之下,而大多数机器学习人员会将其置于“超平面”下,并进行logistic回归。
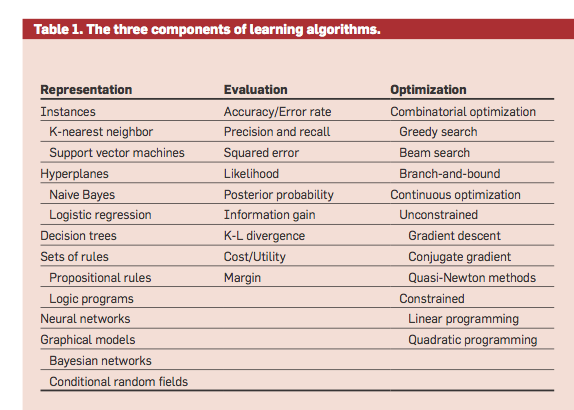
此外,在他的讲演幻灯片中,他给出了这样的推理:


有人能解释一下这种推理吗?为什么支持向量机是一个基于实例的学习者(如KNN)而不是线性分类器(如logistic回归)?
回答 2
Stack Overflow用户
发布于 2014-10-28 09:00:35
支持向量机是一种基于实例的学习算法,因为如果不能表示特征空间,则需要记住支持向量,因此需要显式地表示该空间中的超平面。
如果使用径向基函数核,则决策边界将由每个支持向量周围的高斯凸起组成,这与使用加权于kNN的支持向量的alpha_i分类器接近。
Stack Overflow用户
发布于 2014-10-28 00:23:55
我认为最好直接问多明戈斯教授。
SVMs确实采用了超平面--毕竟两者都是二进制的。然而,将支持向量机与LR公式进行比较--与LR不同的是,SVM并不是概率性的。虽然可以肯定地说,所有的ML都是基于实例的。
https://stackoverflow.com/questions/26598514
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号