
一种用于多类分类的基本前馈感知神经网络
我是新的神经网络,我想创建一个前馈神经网络的多类分类。我可以使用任何公开的代码,但不是任何MATLAB ToolBox,因为我没有访问它的权限(所以没有神经网络工具箱)。目标是将数据分类为10个类中的一个。这是数据集,类由最后一列中的三个字母代码定义。
在创建神经网络时,您是否简单地定义了节点的数量,并让层中的每个节点连接到层i+1中的每个节点?然后让他们自己学习举重?
还有一个来源,我可以遵循的MATLAB代码,创建一个神经网络的任何数量的输入,任何数量的节点,并进行多类分类,即前馈。
回答 2
Stack Overflow用户
发布于 2014-10-22 09:53:22
对神经网络的概括性介绍(看来你还需要了解一下它们是什么):96/journal/vol4/96 11/report.html
阅读本文档,解释前馈网络如何利用反向传播工作(数学是重要的):en/backpro.html
这里有一个在matlab中有注释的实现:http://anoopacademia.wordpress.com/2013/09/29/back-propagation-algorithm-using-matlab/
关于你的问题:
1)“在创建神经网络时,您是否简单地定义了节点的数量,并让I层中的每个节点连接到层i+1中的每个节点?”取决于您使用的网络。在简单的完全连接的前馈神经网络中,是的。
2)“然后让他们自己学习重量?”这就是一般的想法。你有一些数据,你知道他们的类(监督学习),你将提供给神经网络学习模式,在学习结束后,你使用这个更新的权重来分类新的,看不见的数据。
Stack Overflow用户
发布于 2014-10-23 01:12:26
对于这类多类问题(特别是评估问题),应该使用交叉熵错误而不是分类错误或均方错误。这是一篇很好的文章,它解释了这个想法。我将在此引用它的例子:
假设我们从年龄、性别、年收入等独立数据中预测一个人的政党归属(民主党,共和党,其他)。..。 现在假设您只有三个训练数据项。您的神经网络使用softmax激活输出神经元,因此有三个输出值可以解释为概率。例如,假设神经网络的计算输出,目标(也就是期望的)值如下所示:
computed | targets | correct?
-----------------------------------------------
0.3 0.3 0.4 | 0 0 1 (democrat) | yes
0.3 0.4 0.3 | 0 1 0 (republican) | yes
0.1 0.2 0.7 | 1 0 0 (other) | no该神经网络的分类误差为1/3 = 0.33。注意,NN --仅仅是--几乎没有得到前两个训练项的正确,而且离第三个训练项还有很远的距离。现在看到另一个输出如下:
computed | targets | correct?
-----------------------------------------------
0.1 0.2 0.7 | 0 0 1 (democrat) | yes
0.1 0.7 0.2 | 0 1 0 (republican) | yes
0.3 0.4 0.3 | 1 0 0 (other) | no该神经网络的分类误差为1/3 = 0.33。但是第二个神经网络比第一个神经网络要好得多,因为它确定了前两个训练项目,几乎没有错过第三个训练项目。总结说,分类误差是一种非常粗略的误差度量。在下面对这两种情况下的分类误差和平均交叉熵误差进行了比较:
Neural Network | classification error | Average cross-entropy error
--------------------------------------------------------------------
NN1 | 0.33 | 1.38
NN2 | 0.33 | 0.64要在培训中使用交叉熵误差,需要使用不同的成本函数.参见详细信息这里。
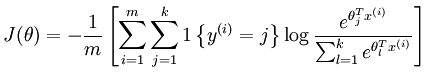
其中m是训练示例的数量,k是类的数量;y是标签;x是特征向量;\theta是权重参数。
https://stackoverflow.com/questions/26499702
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号