
小批渐变体面和梯度体面之间是否有固定的关系?
对于凸优化,类似于logistic回归。
例如,我有100个训练样本。在mini batch gradient decent中,我将批处理大小设置为10。
因此,经过10次mini batch gradient decent更新。我可以通过一次gradient decent 更新获得相同的结果吗?
对于非凸优化,如神经网络.
我知道mini batch gradient decent有时可以避免局部最优。,但它们之间是否有固定的关系.
回答 1
Stack Overflow用户
发布于 2014-10-17 00:34:09
当我们说批梯度下降,它是更新参数使用所有的数据。下面是批处理梯度下降的示例。注意,批处理梯度下降的每一次迭代都需要计算整个训练数据集中损失函数的平均梯度。在图中,-gamma是负值的学习率。
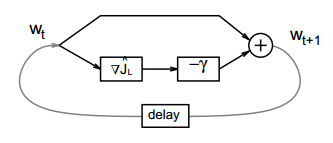
当批数为1时,称为随机梯度下降(GD)。
当您将批处理大小设置为10 (我假设总训练数据大小为>>10)时,这种方法称为小批随机GD,它是真正的随机GD和批GD (在一次更新时使用所有培训数据)之间的折衷。迷你批次比真正的随机梯度下降更好,因为当每一步计算的梯度使用更多的训练示例时,我们通常会看到更平滑的收敛。下面是SGD的一个例子。在这个在线学习环境中,每次更新的迭代都包括从外部选择一个随机训练实例(z_t)并更新参数w_t。
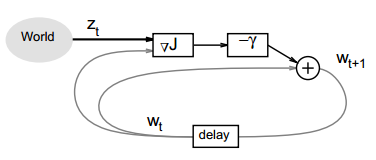
我在这里包含的两个数字来自于这个纸。
来自维基
利用凸极小化和随机逼近理论分析了随机梯度下降的收敛性。简单地说,当学习速率α随着适当的速率降低,在相对温和的假设下,当目标函数是凸或伪凸时,随机梯度下降几乎必然收敛到全局极小,而在其他情况下则几乎肯定收敛到局部极小。这实际上是罗宾斯-西格蒙德定理的结果。
关于你的问题:
[convex case] Can I get the same result with one times gradient decent updating?如果“相同结果”的意思是“收敛”到全球最小值,那么是的。这是L‘eon在他的纸中批准的。也就是说,SGD或小型批量SGD几乎肯定会收敛到一个全球最小值。注意,当我们几乎肯定地说:
然而,很明显,任何在线学习算法都可能被不可能的例子的一致选择所误导。因此,没有希望证明该算法总是收敛的。因此,最好的结果是几乎确定的收敛性,即该算法以1的概率收敛到解。
对于非凸情形,在同一文献(第5节)中也证明了随机或小批几乎肯定地收敛到局部极小。
https://stackoverflow.com/questions/26398555
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号