
余弦相似-缺点作为推荐引擎?
我见过在K-最近邻算法中使用余弦相似性来生成基于用户偏好的推荐。在这些模型中,将给定产品的用户等级作为向量,然后由两个向量之间的余弦相似度来确定两个用户之间的相似度。(例如http://www.neo4j.org/graphgist?8173017)
我的问题是:能解释使用Cosine相似性的推荐引擎是如何计算出并行用户偏好的吗?在我看来,有两个用户可以拥有完全极高的评级偏好,但如果他们有平行(但不同的)偏好,那么就会生成一个余弦相似度为1。例如,如果一个用户将5部电影评为10颗星中的1部,而另一位用户将相同的5部电影评为10颗星中的10部,那么它们的Cosine相似性将为1(在我看来,这似乎是衡量用户相似性的一种不准确的方法)。
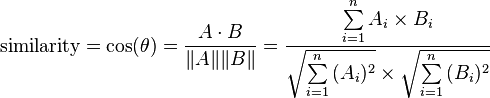
问题的例子:如果我们测量两个用户的用户偏好,并且测量他们对3种产品的偏好,我们可以将他们的偏好存储为两个向量:
A =(1,1,1)和b=(10,10,10)
然后,我们可以用余弦相似性来衡量它们之间有多相似。但在这种情况下,它们的余弦相似性将为1,尽管它们代表的是极性相反的用户首选项。
回答 1
Stack Overflow用户
发布于 2014-10-07 22:20:45
这是众所周知的,香草余弦的相似性有一个重要的缺点,-the的差异,在不同的用户之间的评分没有考虑到。
调整后的余弦相似度通过从每个同级对中减去相应的用户平均值来弥补这一缺点。形式上,使用该方案给出了项目i和j之间的相似性。
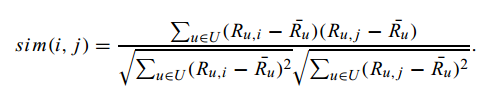
在这里,R¯u是u用户的平均评分。
在您的示例中,经过预处理后,a和b都变成
(0,0,0). // We cannot calculate the cosine similarity since the normalizer is 0. 这在现实中是很少见的(同样,如果用户对每一项都给予相同的评分,那么理解用户或项目都没有任何贡献)。
假设我们在每个用户的偏好向量中添加另一个偏好分数,以使相似度可以计算。
a = (1,1,1,2)
b = (10,10,10,8)
a1 = (1,2,2,1) // a user that has similar preference to a
b1 = (9,8,9,10) // another user that has similar preference to b
norm_a = a - mean(a) = [-0.25000 -0.25000 -0.25000 0.75000]
norm_b = b - mean(b) = [0.50000 0.50000 0.50000 -1.50000]
norm_a1 = [-0.50000 0.50000 0.50000 -0.50000]
norm_b1 = [0 -1 0 1]
sim(a,b) = norm_a*norm_b / (sqrt(sum(norm_a.^2)) * sqrt(sum(norm_b.^2))) = -1同样:
sim(a,a1) = 0.866
sim(b,b1) = -0.82https://stackoverflow.com/questions/26245699
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号