
通过为R中每个条形图的不同段指定名称,使直方图更加清晰
通过为R中每个条形图的不同段指定名称,使直方图更加清晰
提问于 2014-09-30 04:49:14
假设我有一个有两列19行的数据框架(见下文);左列是细胞系的名称,右边的是基因ZEB1在相应细胞系中的表达。
CellLines ZEB1
600MPE 2.8186
AU565 2.783
BT20 2.7817
BT474 2.6433
BT483 2.4994
BT549 3.035
CAMA1 2.718
DU4475 2.8005
HBL100 2.6745
HCC38 3.2884
HCC70 2.597
HCC202 2.8557
HCC1007 2.7794
HCC1008 2.4513
HCC1143 2.8159
HCC1187 2.6372
HCC1428 2.7327
HCC1500 2.7564
HCC1569 2.8093我使用以下简单代码绘制了该数据的直方图:
hist(Heiser$ZEB1[1:19], breaks=50, col="grey")它给出了一个直方图,它的x轴是基因表达量,y轴是细胞在细胞中表达的频率,但是,我想在直方图上的特定位置加上细胞系的名称。我怎么能这么做?
谢谢你花时间回答这个问题:-)最好的。
回答 2
Stack Overflow用户
回答已采纳
发布于 2014-09-30 05:06:50
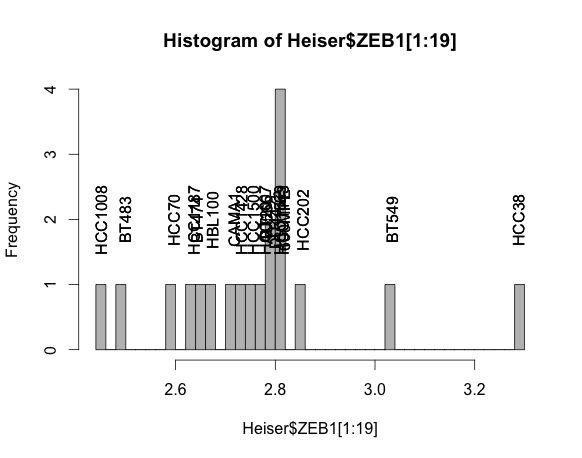
另一种选择是使用text将标签插入到绘图中:
hist(Heiser$ZEB1[1:19], breaks=50, col="grey")
text(Heiser$ZEB1, 2, labels= Heiser$CellLines, srt=90)
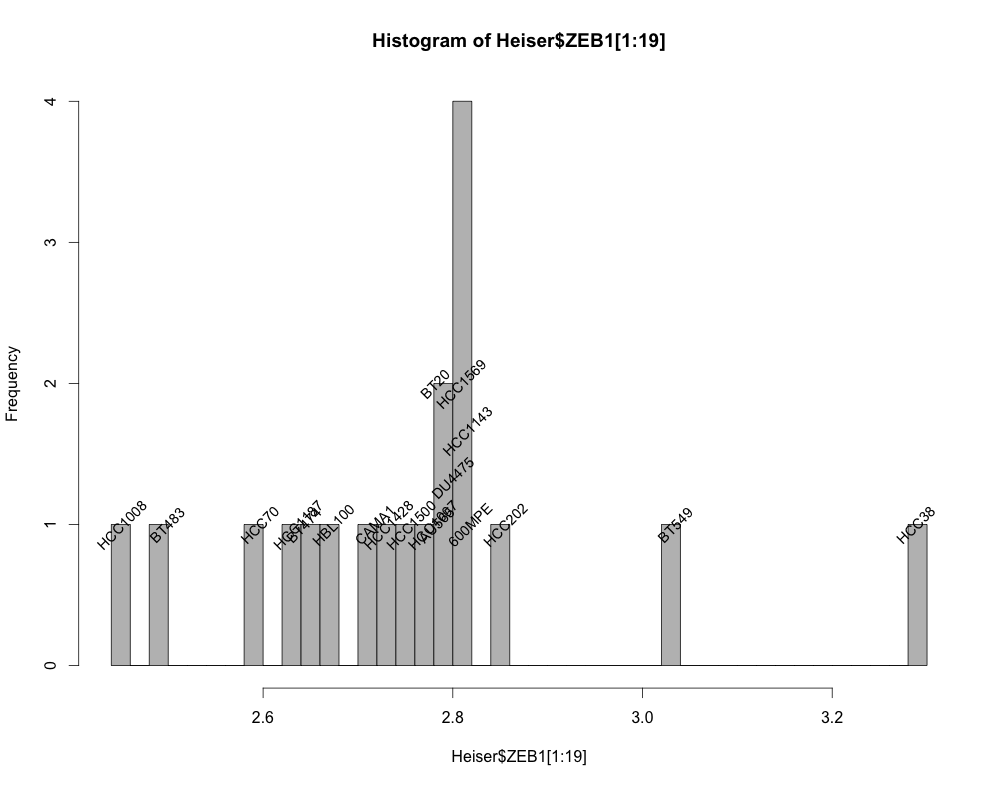
编辑:
将同一类别的标签放置在另一类上:
Heiser_hist <- hist(Heiser$ZEB1[1:19], breaks=50, col="grey")
Heiser$cut <- cut(Heiser$ZEB1, breaks=Heiser_hist$breaks)
library(dplyr)
Heiser <- Heiser %>% group_by(cut) %>% mutate(pos = seq(from=1, to=2, length.out=length(ZEB1)))
with(Heiser, text(ZEB1, pos, labels=CellLines, srt=45, cex=0.9))
您可以在不改变srt的情况下尝试文本,但是在这种情况下,过度绘制会更糟。您还可以使用x轴来减少过度绘制。
Stack Overflow用户
发布于 2014-09-30 04:59:44
你会遇到重叠标签的问题(不确定你想要做什么),但是
hist(Heiser$ZEB1[1:19], breaks=50, col="grey", xaxt="n")
axis(1,Heiser$ZEB1, Heiser$CellLines )我想根据描述告诉你你想要的是什么。
你确定你不想要酒吧阴谋吗?因为有了直方图,一个条形并不代表一个观察。直方图是对连续变量的潜在概率密度函数的估计。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/26112990
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号