
OpenGL理解两个视图来查看模型转换
有两种观点来理解模型转换,我阅读了红皮书第七版,大,固定坐标系和移动的地方坐标系。
我的问题是:
这两种观点之间有什么区别,以及何时在特定情况下使用它们?
附加上下文信息:
我想给你一些背景来帮助我,或者你可以忽略下面的细节。
我在下面的way.Think中理解了这两个观点--我有以下代码:(不推荐使用glTranslatef之类的函数,代之以数学库,但理论可能会有所帮助。)
//render the sence,and use orthogonal projection
void display( void )
{
glClear(GL_COLOR_BUFFER_BIT|GL_DEPTH_BUFFER_BIT);
glLoadIdentity();
drawAixs(4.8f);//draw x y z aixs,4.8 is axis length
glRotatef(45.0,0.0,0.0,1.0);
glTranslatef(3.0,0.0,0.0);
glutSolidCube(2.0);
glutSwapBuffers();
}本地坐标视图中的 :
从这个角度来看,我们可以这样理解:
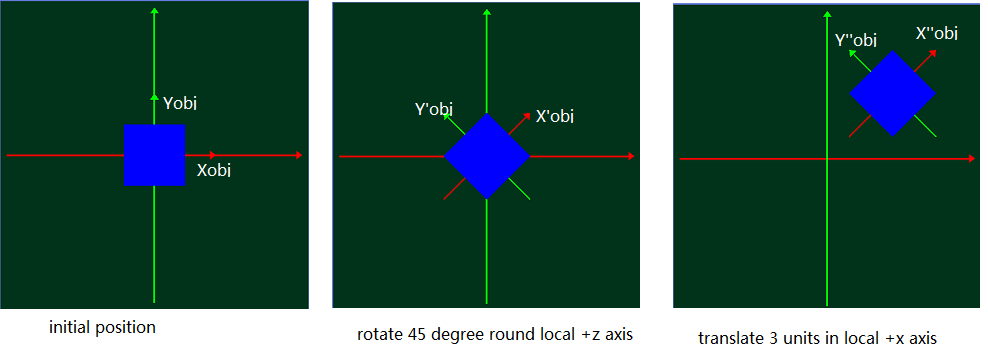
目前的转换矩阵(CTM)是:
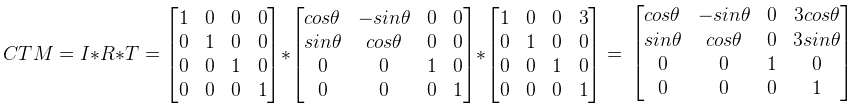
来自全局固定坐标视图的 :
从这个角度来看,我们可以得到:
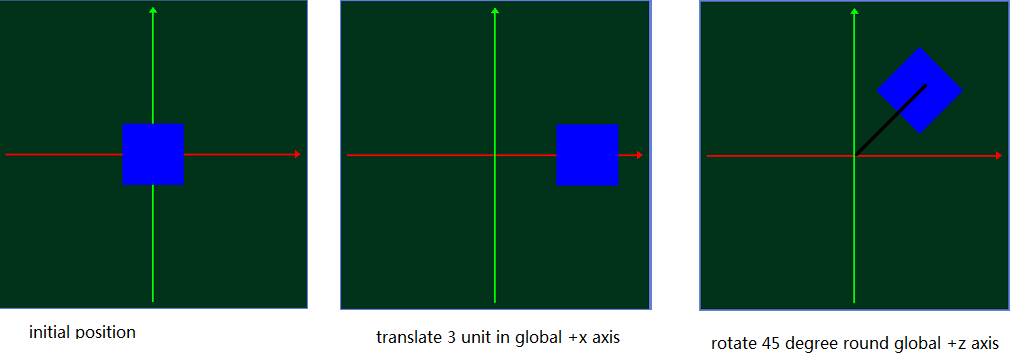
回答 1
Stack Overflow用户
发布于 2014-09-29 12:06:11
这两个坐标系只是一个惯例。总有一个全局坐标系,但可能有许多局部系统。地方制度的概念只是一种惯例。一个一般的变换矩阵M将顶点从一个空间转换到另一个空间:
v' = M * v所以v在一个坐标空间,v'在另一个坐标空间。如果M描述一个物体的位置,我们说它是把从局部物体坐标系到全局世界坐标系的顶点。另一方面,如果它描述相机的位置和投影,它将从世界坐标系到另一个局部眼睛坐标系的顶点。
具有关节的复杂对象(例如类人形字符,或带有铰链的机构)实际上可能有几个中间的局部空间,其中转换是链式的,这取决于对象骨架的结构。
通常使用object space定义模型的顶点,world space是一个全局空间,坐标可以相互关联,camera space或eye space是屏幕坐标的空间。但是,随着OpenGL 3着色器的引入,这些着色器完全是任意的:您可以编写着色器,以便它使用一个矩阵将顶点从对象空间直接转换为屏幕空间。因此,不要担心坐标框架,只需关注手头的任务--您想要显示的是什么,以及对象应该如何移动(相对于彼此或相对于某些公共引用)。
https://stackoverflow.com/questions/26095492
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号