
基于n字元特征的相似性度量
我使用以下代码从单词中提取出双字母:
Scanner a = new Scanner(file1);
PrintWriter pw1= new PrintWriter(file2);
while (a.hasNext()) {
String gram=a.next();
pw1.println(gram);
int line;
line = gram.length();
for(int x=0;x<=line-2;x++){
pw1.println(gram.substring(x, x+2));
}
}
pw1.close();
}
catch(FileNotFoundException e) {
System.err.format("FileNotExist");`
}例如,“学生”的双克是"st“、"tu”、"ud“、"de”、"en“、"nt".
但我需要找到相似性计算。
我必须计算这些分裂的克之间的相似值。
回答 1
Stack Overflow用户
发布于 2014-09-25 13:05:34
嗯,你不是很好地解释你的问题,但这是我的机会。
首先,你的代码到处都是,即使是这么小的一个程序,任何人都很难阅读任何东西,我会编辑它,使它可读性,但我不确定我是否允许。
无论如何,bigram=一对字母、单词或音节(根据Google)。你在找它的相似值吗?
我对它做了一些研究,看起来你需要的算法就是这个。
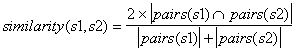
现在,让我们开始充实这个。如果我误解了你的问题,请纠正我。你正在寻找单词之间的相似性,把它们分解成大图,并找到它们各自的相似值,是吗?如果是这样的话,让我们在开始使用之前先分解这个公式,因为它肯定是您所需要的。
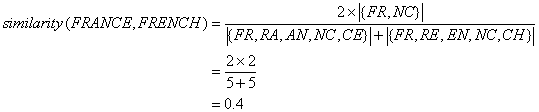
现在,我们有两个词,法国和法语。我们希望找到它们的相似值,如果它们被分解成大图。
对于法国,我们有{FR,RA,AN,NC,CE}
对于法语,我们有{FR,RE,EN,NC,CH}
法国和法国代表的是第一个方程式中的s1和s2。接下来,我们取他们在两个大图中的火柴。我的意思是,在这两个单词中都可以找到哪一个或几个字母?在这种情况下,答案是FR和NC。
因为我们找到了2对,上面的值变成了4,因为公式状态,2乘以匹配的比格数。所以我们上面有4个,没有其他的了。
现在,下面的一半是通过把你正在比较的每一个单词加起来,即法国的5个和法语的5个来计算的。所以分母是10
所以现在,我们有什么?我们有4/10,或.4。,是我们的相似值,这是您在制作程序时需要找到的值。
让我们尝试另一个例子,把它根植在我们的脑海中,比如说
s1 =“歌利亚”
s2 =“守门员”
所以,利用大图,我们找出了字符串数组.
{"GO“、"OL”、"LI“、"IA”、"AT“、"TH"} {"GO”、"OA“、"AL”、"LI“、"IE"}
现在,火柴的数量。这两个单词中有多少匹配的大写??回答- 2,去和李
所以,分子会
2 x {2匹配}=4
现在,分母,Goliath有6个比格,守门员有5个比格。记住,我们必须把这两个值相加到原来的公式中,所以我们的分母是11。
那我们该怎么办??
S(歌利亚,守门员)= 4/11 ~ .364 <-相似值
我在这个链接下找到了公式(基本上是我刚才学到的所有东西),这使事情变得很容易理解。
http://www.catalysoft.com/articles/StrikeAMatch.html
我将编辑这条评论,因为我需要一段时间才能为您的类提供一个方法,但是只是为了快速的响应,如果您正在寻找更多关于如何做它的帮助,这个链接是一个很好的起点。
编辑*
好的,刚为它建立了一个方法,就在这里。
public class BiGram
{
/*
here are your imports
import java.util.Scanner;
import java.io.File;
import java.io.PrintWriter;
import java.io.FileNotFoundException;
*/
//you'll have to forgive the lack of order or common sense, I threw it
//together fast I could cuz it sounded like you were in a rush
public String[][] bigramizedWords = new String[2][100];
public String[] words = new String[2];
public File file1 = new File("file1.txt");
public File file2 = new File("file2.txt");
public int tracker = 0;
public double matches = 0;
public double denominator = 0; //This will hold the sum of the bigrams of the 2 words
public double results;
public Scanner a;
public PrintWriter pw1;
public BiGram()
{
initialize();
bigramize();
results = matches/denominator;
pw1.println("\n\nThe Bigram Similarity value between " + words[0] + " and " + words[1] + " is " + results + ".");
pw1.close();
}
public static void main(String[] args)
{
BiGram b = new BiGram();
}
public void initialize()
{
try
{
a = new Scanner(file1);
pw1 = new PrintWriter(file2);
while (a.hasNext())
{
//System.out.println("Enter 2 words delimited by a space to calculate their similarity values based off of bigrams.");
//^^^ I was going to use the above line, but I see you are using File and PrintWriter,
//I assume you will have the files yourself with the words to be compared
String gram = a.next();
//pw1.println(gram); -----you had this originally, we don't need this
int line = gram.length();
for(int x=0;x<=line-2;x++)
{
bigramizedWords[tracker][x] = gram.substring(x, x+2);
pw1.println(gram.substring(x, x+2) + "");
}
pw1.println("");
words[tracker] = gram;
tracker++;
}
}
catch(FileNotFoundException e)
{
System.err.format("FileNotExist");
}
}
public void bigramize()
{
denominator = (words[0].length() - 1) + (words[1].length() - 1);
//^^ Let me explain this, basically, for every word you have, let's say BABY and BALL,
//the denominator is gonna be the sum of number of bigrams. In this case, BABY has {BA,AB,BY} or 3
//bigrams, same for BALL, {BA,AL,LL} or 3. And the length of the word BABY is 4 letters, same
//with Ball. So basically, just subtract their respective lengths by 1 and add them together, and
//you get the number of bigrams combined from both words, or 6
for(int k = 0; k < bigramizedWords[0].length; k++)
{
if(bigramizedWords[0][k] != null)
{
for(int i = 0; i < bigramizedWords[1].length; i++)
{
///////////////////////////////////////////
if(bigramizedWords[1][i] != null)
{
if(bigramizedWords[0][k].equals(bigramizedWords[1][i]))
{
matches++;
}
}
}
}
}
matches*=2;
}
}https://stackoverflow.com/questions/26037351
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号