
我是否应该将“自旋”线程“绑定”到特定的核心?
我的应用程序包含几个延迟临界线程,这些线程“自旋”,即永不阻塞。这样的线程预计将占用100%的一个CPU核心。然而,现代操作系统似乎经常将线程从一个内核转移到另一个内核。因此,例如,使用此Windows代码:
void Processor::ConnectionThread()
{
while (work)
{
Iterate();
}
}在任务管理器中,我没有看到"100%被占用“核心,总体系统负载是36.40%。
但如果我把它改为:
void Processor::ConnectionThread()
{
SetThreadAffinityMask(GetCurrentThread(), 2);
while (work)
{
Iterate();
}
}然后我看到其中一个CPU内核被100%占用,整个系统负载也减少到34-36%。
这是否意味着我应该倾向于使用SetThreadAffinityMask来“旋转”线程?如果我改进了延迟添加SetThreadAffinityMask在这种情况下?对于“自旋”线程,我还应该做什么来改善延迟呢?
我正在将我的应用程序移植到Linux中,所以这个问题更多的是关于Linux (如果这一点重要的话)。
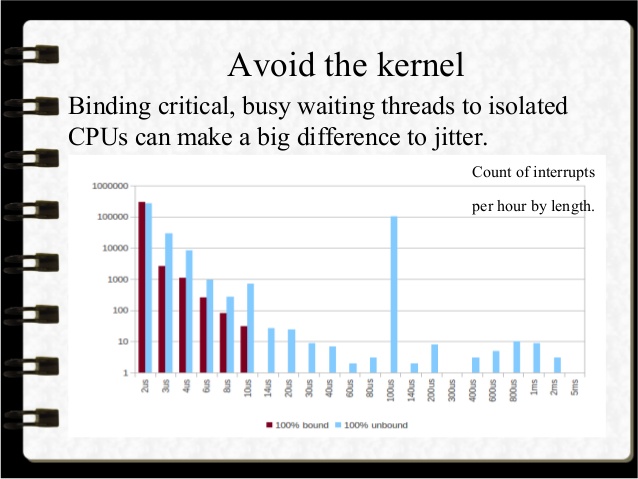
upd发现了这张幻灯片,它表明将繁忙等待线程绑定到CPU可能有帮助:
回答 5
Stack Overflow用户
发布于 2014-09-23 15:59:59
如果在代码中这是最重要的事情,那么在大多数情况下,运行锁定到单个核心的线程会为该线程提供最佳延迟。
理由(R)是
- 您的代码可能在iCache中。
- 分支预测器将调优到您的代码。
- 您的数据可能已经在dCache中准备好了。
- TLB指向您的代码和数据。
除非
- 你在运行SMT系统(前。在这种情况下,邪恶的孪生者会“帮助”你,让你的代码被洗掉,你的分支预测器被调到它的代码,它的数据会把你推出dCache,你的TLB会受到它的使用的影响。
- 成本未知,每个缓存丢失成本~4ns,~15 4ns和~75 4ns的数据,这很快就会达到几个1000 4ns。
- 它为上面提到的每一个R节省下来,那仍然在那里。
- 如果邪恶的孪生兄弟也只是旋转,那么成本就应该要低得多。
- 或者允许核心中断,在这种情况下,您会遇到相同的问题和。
- 你的TLB被冲了
- 您采取1000 if 20000ns击中的上下文切换,大多数应该是在低端,如果司机是很好的编程。
- 或者你允许操作系统切换你的进程,在这种情况下,你会遇到和中断一样的问题,就在这个范围的最高端。
- 切换也可能导致线程暂停整个切片,因为它只能在一个(或两个)硬件线程上运行。
- 或者使用导致上下文切换的任何系统调用。
- 根本没有磁盘IO。
- 只有异步IO其他。
- 与核心相比,具有更多活动线程(无暂停)增加了问题的可能性。
因此,如果您需要少于100 on的延迟,以防止您的应用程序爆炸,您需要防止或减少SMT的影响,中断和任务切换到您的核心。最好的解决方案是一个http://en.wikipedia.org/wiki/RTLinux。这是一个几乎完美的匹配您的目标,但这是一个新的世界,如果你大部分已经完成了服务器和桌面编程。
将线程锁定到单个核心的缺点是:
- 这将花费一些总吞吐量。
- 如果上下文可以被切换的话,可能已经运行的一些线程。
- 但在这种情况下,延迟更重要。
- 如果线程切换了上下文,则需要一段时间才能调度一个或多个时间片(通常为10-16ms ),这在此应用程序中是不可接受的。
- 将它锁定到一个核心和它的SMT将减少这个问题,但不能消除它。每个增加的核心将减少问题。
- 提高其优先地位将减少问题,但不能消除问题。
- 使用SCHED_FIFO和最高优先级的调度将防止大多数上下文切换,中断仍然会导致临时切换,一些系统调用也会造成中断。
- 如果您有一个多cpu设置,您可能可以通过cpuset独占其中一个CPU。这就阻止了其他应用程序使用它。
使用在SU中运行的具有赛特赛德帕拉姆和最高优先级的SCHED_FIFO,并将其锁定到内核和其邪恶的孪生节点上,可以保护所有这些延迟的最佳延迟,只有实时操作系统才能消除所有上下文切换。
其他链接:
关于中断的讨论
您的Linux可能会接受调用集调度器,使用SCHED_FIFO,但这要求您拥有自己的PID,而不仅仅是一个TID,或者您的线程是协作的多任务处理。
这可能并不理想,因为您的所有线程都是“自愿的”开关,从而消除了内核调度它的灵活性。
100中的进程间通信
Stack Overflow用户
发布于 2014-09-21 19:20:00
将任务固定在特定处理器上通常会为任务提供更好的性能。但是,在这样做的时候,有很多细微差别和成本需要考虑。
强制执行关联时,会限制操作系统的调度选择。增加剩余任务的cpu争用。因此,包括操作系统本身在内的系统上的所有其他都会受到影响。您还需要考虑的是,如果任务需要跨内存通信,并且将关联设置为不共享缓存的cpus,则可以大大增加跨任务通信的延迟。
但是,设置任务cpu亲和力的最大原因之一是它提供了更可预测的缓存和tlb ()行为。当任务切换cpu时,操作系统可以将其切换到无法访问上一个cpu的缓存或tlb的cpu。这会增加任务的缓存丢失。这尤其是一个跨任务交流的问题,因为跨越更高级别的缓存和最坏的内存需要更多的时间。要在linux上测量缓存统计信息(一般性能),我建议使用perf。
最好的建议是,在你试图修复亲缘关系之前,先衡量一下。量化延迟的一个好方法是使用rdtsc指令(至少在x86上)。这将读取cpu的时间源,这通常会提供最高的精度。跨事件的测量将提供大约纳秒的精度。
volatile uint64_t rdtsc() {
register uint32_t eax, edx;
asm volatile (".byte 0x0f, 0x31" : "=d"(edx), "=a"(eax) : : );
return ((uint64_t) edx << 32) | (uint64_t) eax;
}- 注-
rdtsc指令需要与负载栅栏相结合,以确保所有以前的指令都已完成(或使用rdtscp)。 - 还请注意-如果使用
rdtsc时没有固定的时间源(在linuxgrep constant_tsc /proc/cpuinfo上,则在频率变化和任务切换cpu (时间源)时可能得到不可靠的值。
因此,一般来说,是的,设置亲和力确实会降低延迟,但这并不总是正确的,而且当您这样做时会付出非常严重的代价。
一些额外的阅读..。
- Intel 64体系结构处理器拓扑枚举
- 每个程序员都需要知道关于内存的事情 (第2、3、4、6和7部分)
- Intel软件开发人员参考 (第2A/2B卷)
- 渡槽和释放栅栏
- TCMalloc
Stack Overflow用户
发布于 2016-06-15 21:45:01
我遇到这个问题是因为我处理的是同一个设计问题。我正在建造一套HFT系统,每毫秒计一纳秒。在阅读了所有答案之后,我决定实现4种不同的方法并对其进行基准测试。
- 没有关联集的繁忙等待
- 用关联集忙碌等待
- 观测器模式
- 信号
不可动摇的胜利者是“忙碌的等待与亲和力的集合”。这一点毫无疑问。
现在,正如许多人所指出的,为了允许操作系统自由运行,一定要让两个内核免费运行。
在这一点上,我唯一关心的是,对于那些100%运行数小时的内核是否有一些物理伤害。
https://stackoverflow.com/questions/25933912
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号