
Akka簇类型
Akka簇类型
提问于 2014-09-11 00:15:10
我正试图了解Akka中的集群是如何工作的。具体来说,我对两种不同类型的集群感兴趣:
- 异构节点,其中集群中的每个“节点”都包含不同行为者的混合;
- 同质节点,其中每个节点分离所有相同类型的行为者。
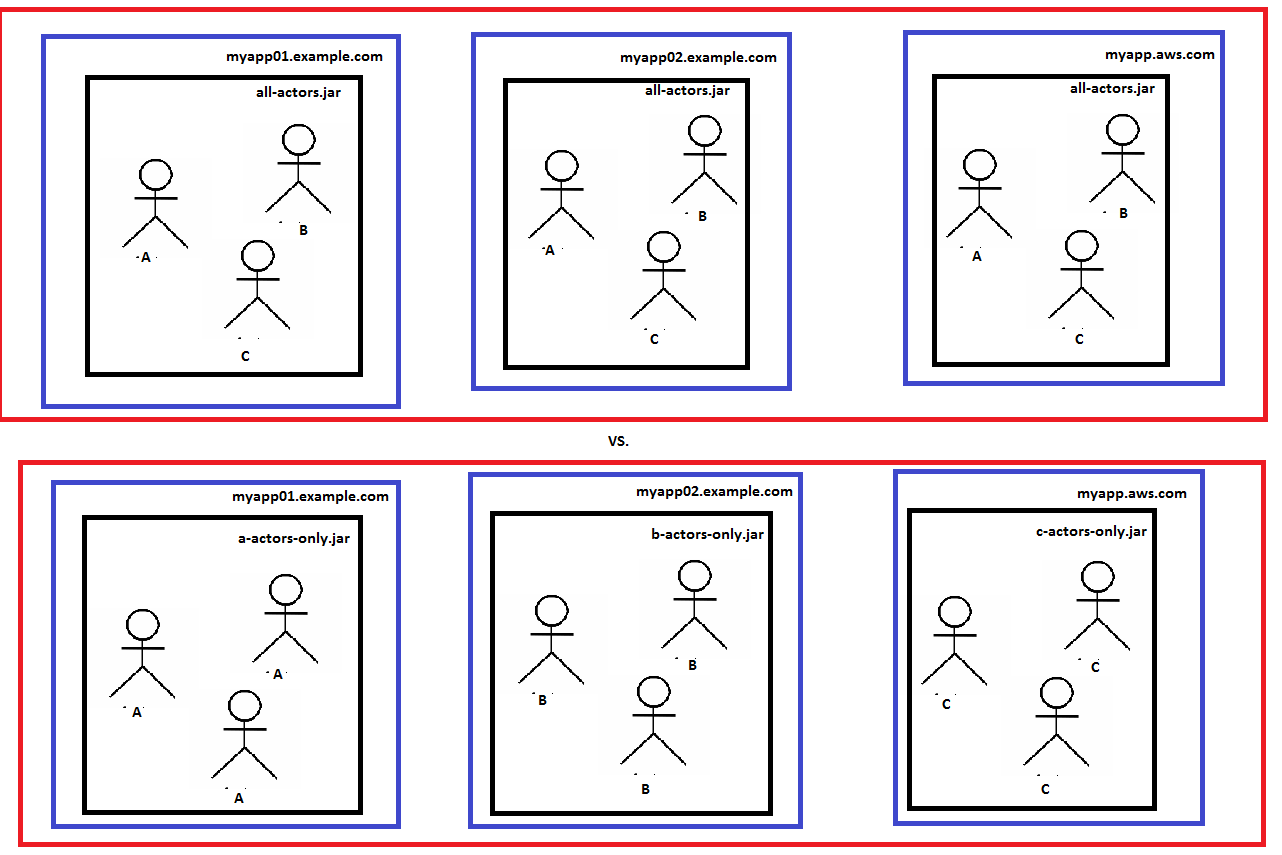
上面是我所说的异质和同质节点的例子。在第一个(顶部)图中,all-actors.jar被部署到三台机器上:myapp01、myapp02和AWS机器。在第二个(底部)图中,部署了3种不同类型的Actor系统;每台机器部署1种。异构模型具有简单性的优点,并使Actor系统作为一个整体具有可伸缩性。同质模型允许更细粒度的弹性(也许我们需要比"A“或"C”更多的"B“角色,等等)。
- Akka是否支持这两种类型的聚类(异质性和同质性)?如果没有,需要什么(在现有集群的基础上添加)才能获得这些集群策略?如果是,如何配置每种类型?
- 是否可以控制每个节点中您想要的Actor的数量?有可能说“在
myapp01上我想要500 A-演员,200 B-演员和1,000 C-演员”吗?或者,Akka只是对消息传递的需求做出反应,并自动地扩大/缩小不同的Actor?
回答 1
Stack Overflow用户
发布于 2014-09-13 00:10:51
经过深入研究,Akka集群与跨JVM的Actor系统集群无关,但实际上它将每个Actor的数据保存在一个同步的内存缓存中,以便如果执行Actor的线程被中断或死亡,Actor的数据可以用于重新生成运行相同类型Actor的新线程。
所以Akka聚类就像橡皮檫,而不是好莱坞演员,而是Akka演员。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/25777079
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号