
R函数用于根据更近的词的频率对单词进行校正
R函数用于根据更近的词的频率对单词进行校正
提问于 2014-09-09 19:36:33
我有一张有拼错字的桌子。我需要纠正那些使用的词更类似于那个,一个有更多的频率。
例如,在我跑完之后
aggregate(CustomerID ~ Province, ventas2, length)我得到了
1
2 AMBA 29
3 BAIRES 1
4 BENOS AIRES 1
12 BUENAS AIRES 1
17 BUENOS AIRES 4
18 buenos aires 7
19 Buenos Aires 3
20 BUENOS AIRES 11337
35 CORDOBA 2297
36 cordoba 1
38 CORDOBESA 1
39 CORRIENTES 424所以我需要用布宜诺斯艾利斯取代布宜诺斯艾利斯,布宜诺斯艾利斯,贝尔斯,布宜诺斯艾利斯,但是AMBA不应该被取代。同样,CORDOBESA和CORDOBA应该被cordoba取代,而不是CORRIENTES。
我怎样才能在R中做到这一点?
谢谢!
回答 2
Stack Overflow用户
回答已采纳
发布于 2014-09-09 21:56:40
这是一个可能的解决方案。
免责声明:
这段代码在当前示例中似乎运行得很好。我不能保证现有的参数(如切割高度、聚类聚集法、距离法等)。将对您的真实(完整)数据有效。
# recreating your data
data <-
read.csv(text=
'City,Occurr
AMBA,29
BAIRES,1
BENOS AIRES,1
BUENAS AIRES,1
BUENOS AIRES,4
buenos aires,7
Buenos Aires,3
BUENOS AIRES,11337
CORDOBA,2297
cordoba,1
CORDOBESA,1
CORRIENTES,424',stringsAsFactors=F)
# simple pre-processing to city strings:
# - removing spaces
# - turning strings to uppercase
cities <- gsub('\\s+','',toupper(data$City))
# string distance computation
# N.B. here you can play with single components of distance costs
d <- adist(cities, costs=list(insertions=1, deletions=1, substitutions=1))
# assign original cities names to distance matrix
rownames(d) <- data$City
# clustering cities
hc <- hclust(as.dist(d),method='single')
# plot the cluster dendrogram
plot(hc)
# add the cluster rectangles (just to see the clusters)
# N.B. I decided to cut at distance height < 5
# (read it as: "I consider equal 2 strings needing
# less than 5 modifications to pass from one to the other")
# Obviously you can use another value.
rect.hclust(hc,h=4.9)
# get the clusters ids
clusters <- cutree(hc,h=4.9)
# turn into data.frame
clusters <- data.frame(City=names(clusters),ClusterId=clusters)
# merge with frequencies
merged <- merge(data,clusters,all.x=T,by='City')
# add CityCorrected column to the merged data.frame
ret <- by(merged,
merged$ClusterId,
FUN=function(grp){
idx <- which.max(grp$Occur)
grp$CityCorrected <- grp[idx,'City']
return(grp)
})
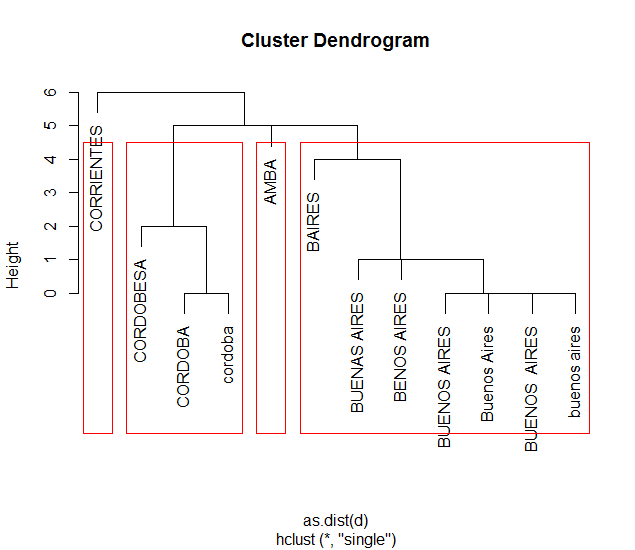
fixed <- do.call(rbind,ret)结果:
> fixed
City Occurr ClusterId CityCorrected
1 AMBA 29 1 AMBA
2.2 BAIRES 1 2 BUENOS AIRES
2.3 BENOS AIRES 1 2 BUENOS AIRES
2.4 BUENAS AIRES 1 2 BUENOS AIRES
2.5 BUENOS AIRES 4 2 BUENOS AIRES
2.6 buenos aires 7 2 BUENOS AIRES
2.7 Buenos Aires 3 2 BUENOS AIRES
2.8 BUENOS AIRES 11337 2 BUENOS AIRES
3.9 cordoba 1 3 CORDOBA
3.10 CORDOBA 2297 3 CORDOBA
3.11 CORDOBESA 1 3 CORDOBA
4 CORRIENTES 424 4 CORRIENTES集群图:
Stack Overflow用户
发布于 2014-09-09 20:04:49
下面是我对聚合结果的小复制,您将需要更改对数据帧的所有调用,以适应数据的任何结构。
df
#output
# word freq
#1 a 1
#2 b 2
#3 c 3
#find the max frequency
mostFrequent<-max(df[,2]) #doesn't handle ties
#find the word we will be replacing with
replaceString<-df[df[,2]==mostFrequent,1]
#[1] "c"
#find all the other words to be replaced
tobereplaced<-df[df[,2]!=mostFrequent,1]
#[1] "a" "b"现在假设您有下面的dataframe,它包含您的整个数据集,我将只复制一个带有单词的列。
totalData
# [,1]
#[1,] "a"
#[2,] "c"
#[3,] "b"
#[4,] "d"
#[5,] "f"
#[6,] "a"
#[7,] "d"
#[8,] "b"
#[9,] "c" 我们可以通过以下调用,用我们想用的字符串替换所有想要替换的单词
totaldata[totaldata%in%tobereplaced]<-replaceString
# [,1]
#[1,] "c"
#[2,] "c"
#[3,] "c"
#[4,] "d"
#[5,] "f"
#[6,] "c"
#[7,] "d"
#[8,] "c"
#[9,] "c"正如你所看到的,所有的a和b都用c代替,其中其他的单词是相同的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/25752306
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号