
数据集大小是否影响机器学习算法?
因此,想象一下能够获得足够高质量的足够数据(数百万用于培训和测试的数据)。请暂时忽略概念漂移,假设数据是静态的,不会随着时间的推移而改变。根据模型的质量,使用所有这些数据有意义吗?
“大脑与网络”( Brain,http://www.csse.monash.edu.au/~webb/Files/BrainWebb99.pdf)包含了一些关于不同数据集大小的实验结果。他们经过测试的算法经过16,000或32,000个数据点的训练后趋于稳定。然而,由于我们生活在大数据世界,我们可以访问数百万点的数据集,所以这篇论文有点相关性,但非常过时。
最近关于数据集大小对学习算法(朴素贝叶斯、决策树、支持向量机、神经网络等)影响的研究有哪些?
- 什么时候一个学习算法收敛到一个稳定的模型,对更多的数据不再提高质量?
- 这种情况是在50,000次数据点之后发生,还是在200,000次之后,或者仅在1,000,000次之后发生?
- 有经验法则吗?
- 或者一个算法没有办法收敛到一个稳定的模型,达到某种平衡?
我为什么要问这个?想象一下,一个存储空间有限的系统,以及大量独特的模型(拥有自己独特数据集的数千个模型),而没有增加存储的方法。因此,限制数据集的大小很重要。
对此有什么想法或研究吗?
回答 1
Stack Overflow用户
发布于 2014-09-04 16:03:01
我在这个问题上做了硕士论文,所以我碰巧对它有相当多的了解。
在硕士论文的第一部分,我取了一些非常大的数据集(大约5,000,000个样本),并在不同的数据集(学习曲线)上学习,测试了一些机器学习算法。
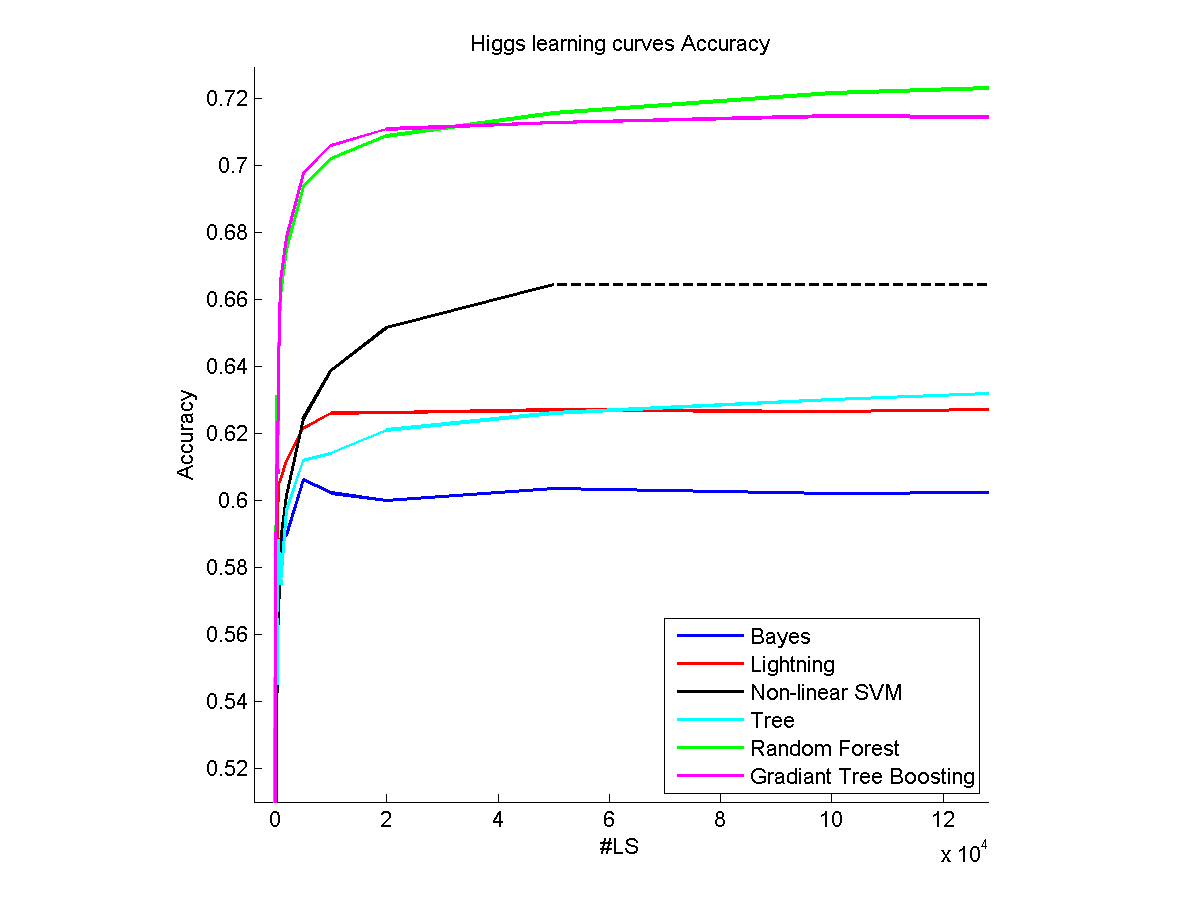
我提出的假设(我主要是使用scikit学习)不是对参数进行优化,而是使用算法的默认参数(出于实际的原因,我不得不提出这个假设,在没有优化的情况下,一些模拟已经在集群上花费了超过24小时)。
首先要注意的是,实际上,每一种方法都会导致数据集的某一部分达到一个平台。然而,由于以下原因,你不能就达到高原所需的有效样本数得出结论:
- 每个数据集都是不同的,对于非常简单的数据集,它们几乎可以提供10个样本所提供的所有内容,而有些数据集在12000个样本之后仍然有一些需要显示的东西(参见上面示例中的Higgs数据集)。
- 数据集中的样本数是任意的,在我的论文中,我用错误的样本测试了一个数据集,这些数据集只是为了混淆算法。
然而,我们可以区分有不同行为的两种不同类型的算法:参数(线性,.)和非参数(随机森林,.)模型。如果一个平台是用一个非参数的,这意味着其余的数据集是“无用的”。正如您所看到的,闪电方法很快就会在我的图片上达到一个平台,这并不意味着dataset没有什么可提供的,但更多的是该方法所能做的最好的。这就是为什么当要得到的模型是复杂的并且能够从大量的训练样本中受益的时候,非参数方法是最好的。
至于你的问题:
- 请参见上面的。
- 是的,这都取决于数据集中的内容。
- 对我来说,唯一的经验法则是交叉验证。如果您认为您将使用20,000或30,000个样本,您通常处于交叉验证没有问题的情况下。在我的论文中,我在测试集上计算了我的方法的准确性,当我没有注意到显著的改进时,我确定了到达那里所需的样本数。正如我说过的,有一些趋势你可以观察到(参数方法比非参数方法更容易饱和)
- 有时,当数据集不够大时,如果您有一个更大的数据集,您可以接受您拥有的每个数据点,并且仍然有改进的余地。在我的论文中,在没有对参数进行优化的情况下,Cifar-10数据集的行为也是如此,即使在5万次之后,我的算法还没有收敛。
我想补充的是,优化算法的参数对收敛到平台的速度有很大的影响,但它需要另一步的交叉验证。
你的最后一句话与我的论文主题高度相关,但对我来说,这句话更多的是与完成ML任务的记忆和时间有关。(如果覆盖的范围小于整个数据集,那么您的内存需求就会更小,而且速度也会更快)。关于这一点,“核心集”的概念对你来说真的很有趣。
我希望我能帮助你,我不得不停下来,因为我可以不停地说,但是如果你需要更多的澄清,我很乐意帮助你。
https://stackoverflow.com/questions/25665017
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号