
用InnoDB引擎在全文搜索中使用连字符?
我在一个零件编号表中有一个全文搜索。有些零件数有连字符。
表引擎是InnoDB,使用MySQL 5.6。
我遇到的问题是,MySQL将连字符(-)作为单词分隔符处理。
因此,我创建了一个新的MySQL字符集排序规则,而连字符被视为一个字母。
我遵循了本教程:http://dev.mysql.com/doc/refman/5.0/en/full-text-adding-collation.html
我使用链接底部的语法创建了一个测试表,但是我使用了InnoDB引擎。我搜索了
但是,如果我将引擎更改为MyISAM,则会得到正确的结果。
如何使它与InnoDB引擎一起工作?
MySQL似乎向前迈进了一步,后退了两步。
编辑:我找到了5.6 (http://dev.mysql.com/doc/refman/5.6/en/full-text-adding-collation.html)的这个链接,这是使用InnoDB作为引擎的同一个教程。
但这是我的测试:
create table test (a TEXT CHARACTER SET latin1 COLLATE latin1_fulltext_ci, FULLTEXT INDEX(a)) ENGINE=InnoDB加了一行就是“-”
select * from test where MATCH(a) AGAINST('----' IN BOOLEAN MODE)语法错误,意外'-‘
放下表,MyISAM
create table test (a TEXT CHARACTER SET latin1 COLLATE latin1_fulltext_ci, FULLTEXT INDEX(a)) ENGINE=MyISAM加了一行就是“-”
select * from test where MATCH(a) AGAINST('----' IN BOOLEAN MODE)1项结果
如果它有助于直观地查看,请编辑2,下面是我的两个测试:
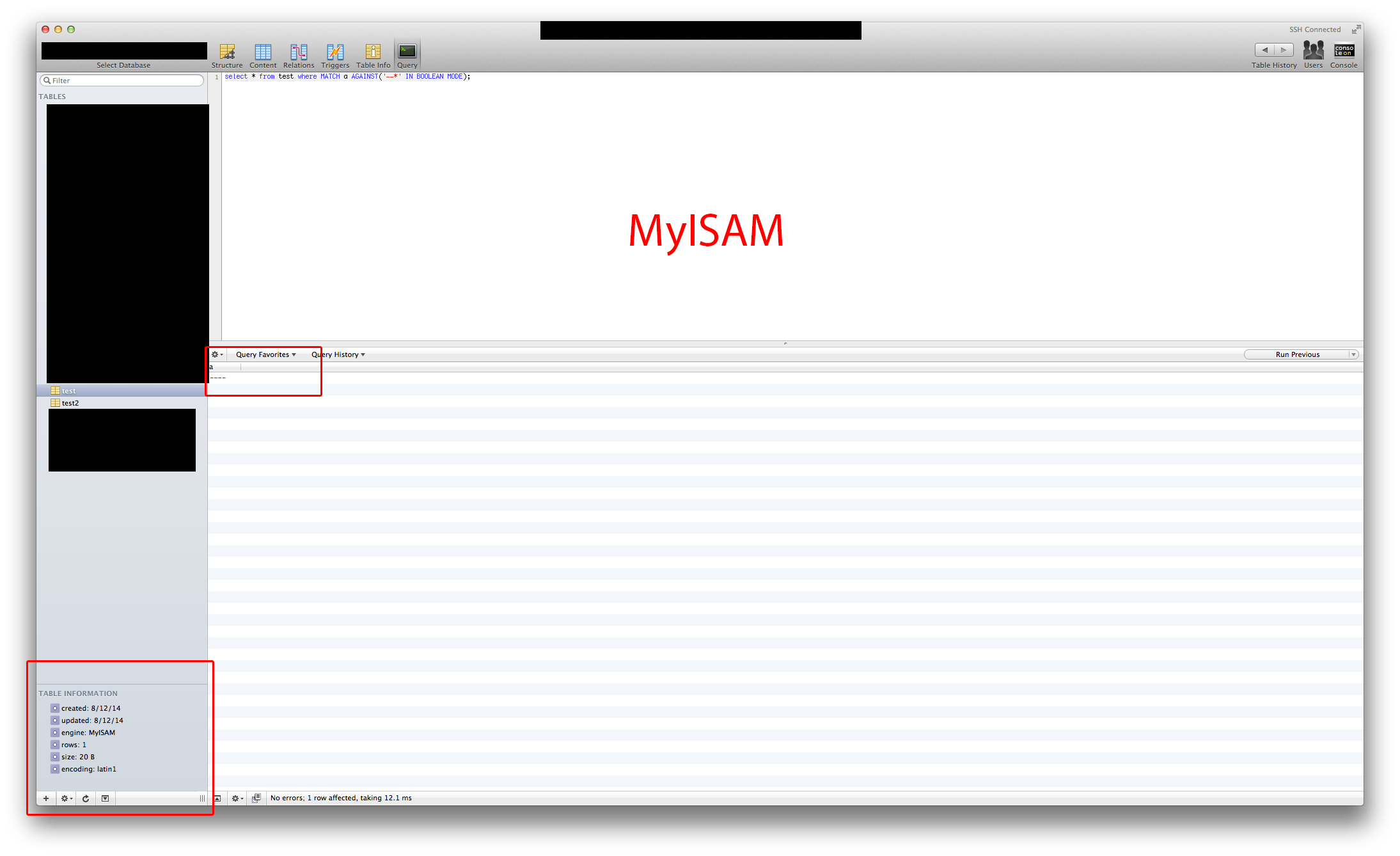
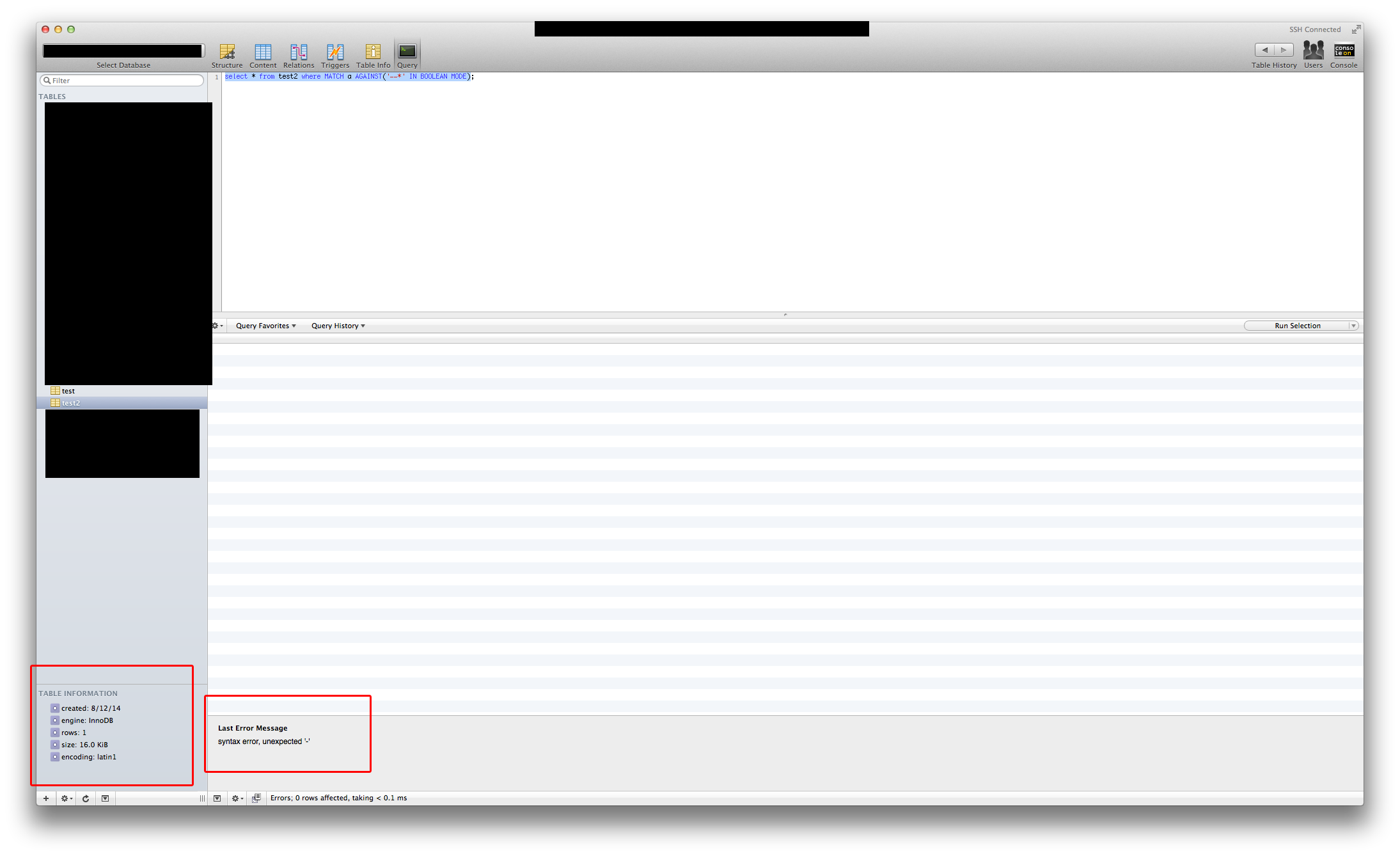
回答 2
Stack Overflow用户
发布于 2019-10-04 18:12:52
我最近遇到了这个问题。以前,我为每个文档添加了一个自定义排序规则,并且使用MyISAM,它运行得很好。几周前,转到InnoDB,一切都停止了。我试过:
- 重建我的校对和A/B测试以确保它们正常工作
- 通过将
innodb_ft_enable_stopword设置为0禁用秒表 - 重建我的全文表和索引
最后,我采取了一种不同的方法,因为在全文索引方面,InnoDB似乎不遵循与MyISAM相同的规则。这有点麻烦,但适用于我的应用程序:
- 创建一个包含需要搜索的数据的特殊
search列。该列有一个全文索引,存在的唯一目的是执行全文搜索,而全文搜索在有数百万行的表上仍然非常快速。 - 用未使用的字符搜索/替换
search列中的所有search字符,该字符被视为"word“字符。请看我在这里的问题:https://dba.stackexchange.com/questions/248607/which-characters-are-considered-word-characters。找出哪个字不是那么容易,但是下面有几个对我有用的词:Ωœπµ。这些字符可能不会在您需要搜索的数据中使用,但是解析器会将它们识别为可搜索的字符。在我的例子中,我将-替换为Ω。因为我只需要行ID,所以这一列中的数据在人眼看来并不重要。 - 修改我的更新和插入以保持
search列数据和替换的更新。在我的例子中,这很容易,因为应用程序中只有一个位置可以更新这个特定的表。还可以使用几个触发器来处理这个问题: 在更新每个行集的动物之前创建触发器update_search NEW.search =NEW.animal_name(NEW.animal_name,'-','Ω');在为每个行集NEW.search = insert_search插入触发器insert_search之前创建触发器insert_search(NEW.animal_name,'-','Ω'); - 将搜索查询中的
-替换为Ω。
瞧。这里有一个小提琴演示:https://www.db-fiddle.com/f/x1WZpZP6wcqbTTvTEFFXYc/0
上述解决方案可能并不适合每个应用程序,但希望它对某些人有用。如果能为InnoDB找到一个真正的解决方案,那就太好了。
Stack Overflow用户
发布于 2014-09-22 12:28:06
InnoDb全文搜索可能将连字符视为停止词。因此,当它到达第二个连字符时,它会期望一个词,而不是连字符。这将解释“语法错误”。
为什么在MyISAM中不这样做,是因为全文索引在InnoDB中的实现是完全不同的,当然,它们只是在MySQL 5.6中为InnoDB添加的。
你能做些什么?似乎您可以通过一个特殊的表:table来影响停止词的列表。这可以阻止MySQL将连字符视为停止词.
https://stackoverflow.com/questions/25269278
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号