
R与鱼类丰度的相关矩阵
R与鱼类丰度的相关矩阵
提问于 2014-08-06 14:27:17
我有一个由每周取样的鱼类数量组成的数据集。我想要创建一个矩阵,它显示了在特定时期,1种物种的丰度与另一种物种的丰度之间的相关性。做这件事最好的方法是什么?对于这种性质的数据,我可以使用pearson相关吗?
我的数据包括12种和20周。每周都有记录在案的丰富。
例如:
Week species 1 species 2 species 3
1 150 1000 0
2 250 1500 0
3 700 1400 0
4 80 2000 1800
5 0 500 600寻找发生或丰富度或一个物种与另一个物种之间的相关性。
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-08-07 04:12:15
以下基本分析可能有帮助:
ddf = structure(list(Week = 1:5, species1 = c(150L, 250L, 700L, 80L,
0L), species2 = c(1000L, 1500L, 1400L, 2000L, 500L), species3 = c(0L,
0L, 0L, 1800L, 600L)), .Names = c("Week", "species1", "species2",
"species3"), class = "data.frame", row.names = c(NA, -5L))
> ddf
Week species1 species2 species3
1 1 150 1000 0
2 2 250 1500 0
3 3 700 1400 0
4 4 80 2000 1800
5 5 0 500 600随时间排列的不同物种间的相关矩阵( species2与3呈一定的正相关,species1与3呈负相关):
cor(ddf[,2:4])
species1 species2 species3
species1 1.0000000 0.2494514 -0.4905172
species2 0.2494514 1.0000000 0.4699644
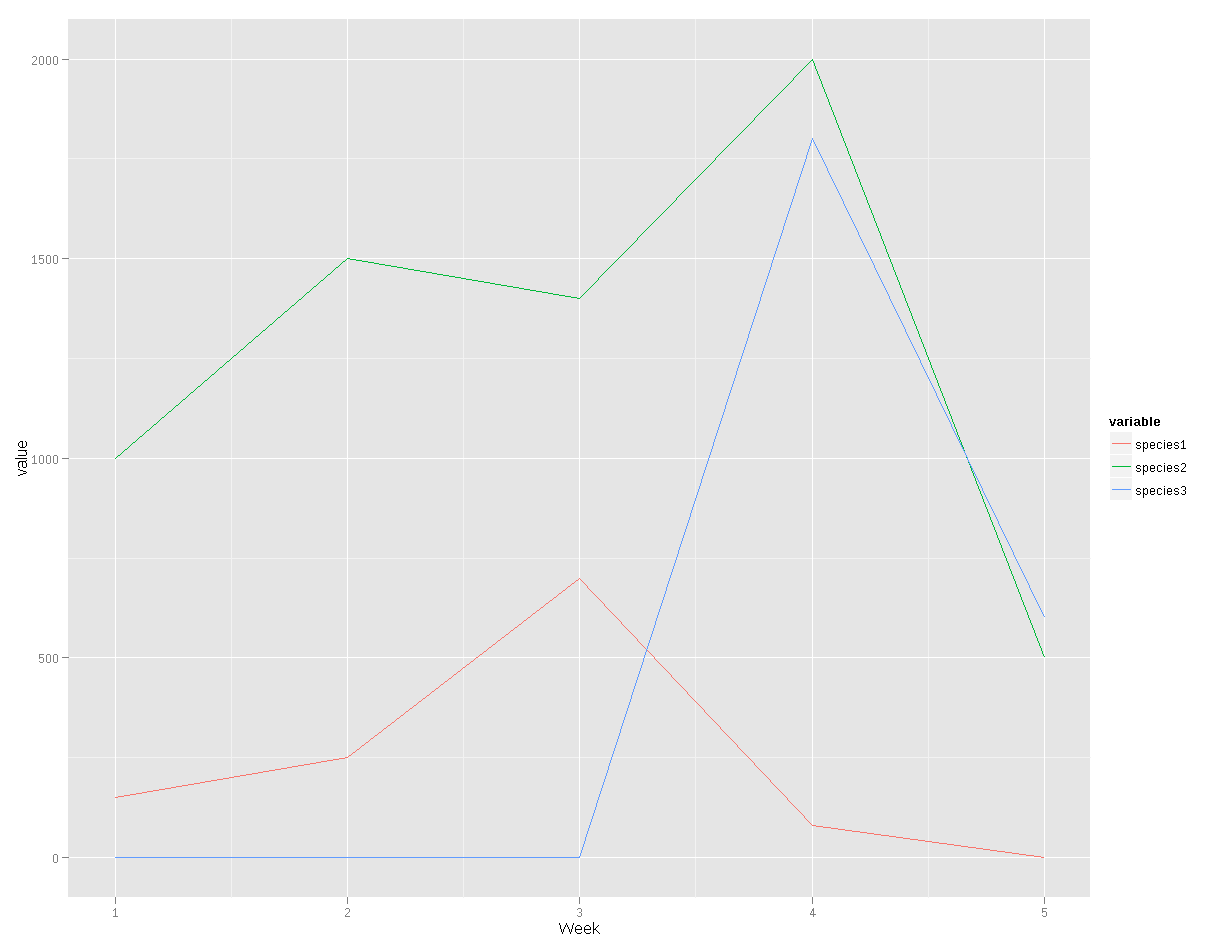
species3 -0.4905172 0.4699644 1.0000000图形表示:
ddfm = melt(ddf, id="Week")
ddfm
Week variable value
1 1 species1 150
2 2 species1 250
3 3 species1 700
4 4 species1 80
5 5 species1 0
6 1 species2 1000
7 2 species2 1500
8 3 species2 1400
9 4 species2 2000
10 5 species2 500
11 1 species3 0
12 2 species3 0
13 3 species3 0
14 4 species3 1800
15 5 species3 600
library(ggplot2)
ggplot(ddfm, aes(x=Week, y=value, group=variable, color=variable)) + geom_line()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/25162997
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号