
将Google Chrome的检查元素放到R中
将Google Chrome的检查元素放到R中
提问于 2014-08-04 13:49:07
这个问题是based on another that I saw closed,它引起了我的好奇心,因为我学到了一些关于Google检查元素的新知识,以创建XML::getNodeSet的HTML解析路径。虽然这个问题已经结束了,因为我认为它可能太宽泛,我将问一个更小,更集中的问题,这可能是问题的根源。
我试图通过编写我通常用来抓取的代码来帮助海报,但是当海报想要谷歌Chrome的检查元素时,我立即撞到了墙上。这与来自htmlTreeParse的HTML不一样,如下所示:
url <- "http://collegecost.ed.gov/scorecard/UniversityProfile.aspx?org=s&id=198969"
doc <- htmlTreeParse(url, useInternalNodes = TRUE)
m <- capture.output(doc)
any(grepl("258.12", m))
## FALSE但是,在Google的检查元素中,我们可以看到提供了这些信息(黄色):
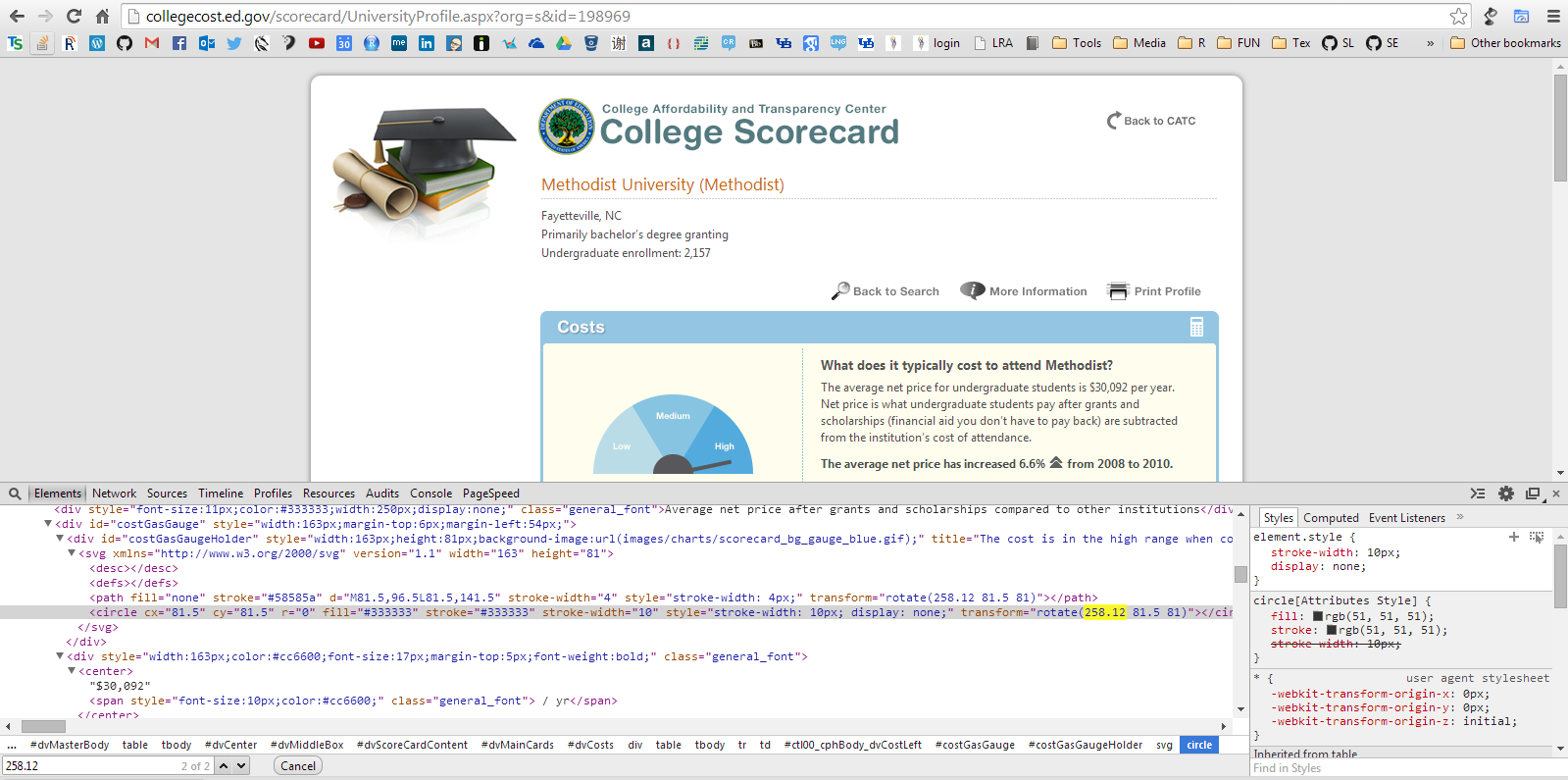
,我们如何才能将Google的检查元素中的信息输入R?,海报显然可以将代码复制并粘贴到文本编辑器中,并以这种方式进行解析,但是他们想要的是刮擦,因此工作流不能扩展。一旦海报能够将这些信息输入R,他们就可以使用典型的HTML解析技术(XLM和RCurl-fu)。
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-08-04 19:10:11
您应该能够使用类似于下面的RSelenium代码来抓取页面。您需要在您的路径上安装和使用java,startServer()行才能工作(因此,您可以做任何事情)。
library("RSelenium")
checkForServer()
startServer()
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444,
browserName = "firefox"
)
url <- "http://collegecost.ed.gov/scorecard/UniversityProfile.aspx?org=s&id=198969"
remDr$open()
remDr$navigate(url)
source <- remDr$getPageSource()[[1]]检查以确保它根据您的测试正常工作:
> grepl("258.12", source)
[1] TRUE页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/25120260
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号