
将成对的shapely函数应用于两个shapely对象的numpy数组
将成对的shapely函数应用于两个shapely对象的numpy数组
提问于 2014-07-24 11:27:37
我有两个不同长度的数组。一个包含形状多边形,另一个包含形状点。我希望为两个数组中的每个元素组合运行a_polygon.contains(a_point) shapely函数。
我认为this post是构建包含行中所有可能组合的两列矩阵的理想中间步骤。但是,当输入数据很大时,‘cartersian(数组)’函数中的循环可能会影响性能。
我尝试广播其中一个数组,然后应用shapely函数:
Polygons_array[:,newaxis].contains(Points_array)但这当然是行不通的。我知道最近发布的地质公园图书馆,但它不是我的阁楼安装的选择。
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-07-24 16:21:39
下面的代码演示如何对包含在两个不同长度数组中的几何对象应用函数。这种方法避免使用循环。熊猫的申请和Numpy的.vectorize和广播选项是必需的。
首先考虑做一些导入和以下两个数组:
import numpy as np
import pandas as pd
from shapely.geometry import Polygon, Point
polygons = [[(1,1),(4,3),(4,1),(1,1)],[(2,4),(2,6),(4,6),(4,4),(2,4)],[(8,1),(5,1),(5,4),(8,1)]]
points = [(3,5),(7,3),(7,6),(3,2)]包含多边形和点的几何对象的数组如下所示:
geo_polygons = pd.DataFrame({'single_column':polygons}).single_column.apply(lambda x: Polygon(x)).values
geo_points = pd.DataFrame({'single_column':points}).single_column.apply(lambda x: Point(x[0], x[1])).values
# As you might noticed, the arrays have different length.现在,要应用于这两个数组的函数已经定义并向量化了:
def contains(a_polygon, a_point):
return a_polygon.contains(a_point)
contains_vectorized = np.vectorize(contains)这样,函数就可以应用于向量中的每个元素。广播点数组处理成对的评估:
contains_vectorized(geo_polygons, geo_points[:,np.newaxis])它返回以下数组:
array([[False, True, False],
[False, False, False],
[False, False, False],
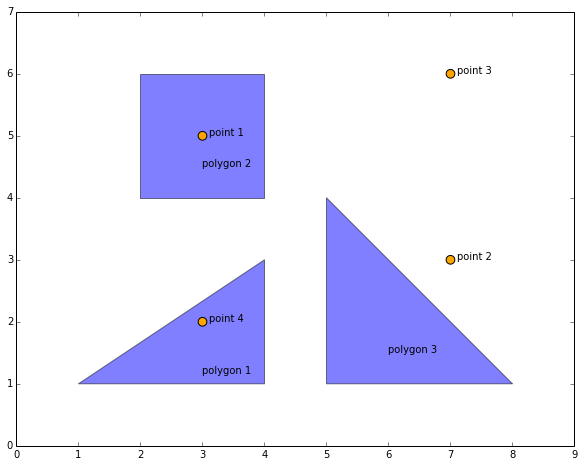
[ True, False, False]], dtype=bool)列对应于多边形,行对应于点。该数组中的布尔值显示,例如,第一个点在第二个多边形内。这也没问题。映射多边形和点将证明这是正确的:
from descartes import PolygonPatch
import matplotlib.pyplot as plt
fig = plt.figure(1, figsize = [10,10], dpi = 300)
ax = fig.add_subplot(111)
offset_x = lambda xy: (xy[0] + 0.1, xy[1])
offset_y = lambda xy: (xy[0], xy[1] - 0.5)
for i,j in enumerate(geo_polygons):
ax.add_patch(PolygonPatch(j, alpha=0.5))
plt.annotate('polygon {}'.format(i + 1), xy= offset_y(tuple(j.centroid.coords[0])))
for i,j in enumerate(geo_points):
ax.add_patch(PolygonPatch(j.buffer(0.07),fc='orange',ec='black'))
plt.annotate('point {}'.format(i + 1), xy= offset_x(tuple(j.coords[0])))
ax.set_xlim(0, 9)
ax.set_ylim(0, 7)
ax.set_aspect(1)
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/24932407
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号