
Polya猜想的反例
Polya猜想是一个数学猜想,它假设第一个(-1)^(欧米茄(N))的和,其中欧米茄(N)是n的多个素数的素数,总是负或零。
一个反例是906316571,是五十年前发现的。我想知道他们怎么会发现它,因为它需要大量的时间,我试图优化我的python算法,但它仍然需要大量的时间,你能帮我优化它吗?
这是我的代码(我用了回忆录)
>>> class Memoize:
def __init__(self, f):
self.f = f
self.memo = {}
def __call__(self, *args):
if not args in self.memo:
self.memo[args] = self.f(*args)
return self.memo[args]
>>> def sieve(m):
n=m+1;
s=[];
for i in range(2,n):
s.append(i);
k=0;
while k<len(s):
for i in range(2,int(n/s[k])+1):
x=i*s[k];
if s.count(x)==1:
s.remove(x);
k=k+1;
return s;
>>> s=sieve(100000);
>>> def omega(n):
k=0;
if n==1:
return 0;
else :
while k<len(s) and n%s[k]!=0 :
k=k+1;
if k<len(s):
return omega(int(n/s[k]))+1;
else :
return 1;
>>> omega=Memoize(omega)
>>> def polya(n):
h=omega(n);
if n==1:
return 0;
else :
if omega(n)%2==0:
return polya(n-1)+1;
else :
return polya(n-1)-1;
>>> polya=Memoize(polya);
>>> while polya(k)<=0 :
k=k+1;回答 1
Stack Overflow用户
发布于 2014-07-05 21:03:18
正如chepner告诉你的,1958年的原始证据不是用蛮力完成的。它也没有揭示出打破规则的最小数目,直到1980年才被发现。我根本没有研究过这件事,但1980年的证据可能是用电脑做的。这更多地是一个可用内存数量的问题,而不是这样的处理速度问题。
然而,有了现代计算机,用蛮力来解决这个问题不应该是公开的困难。Python不是这里最好的选择,但仍然可以在合理的时间内找到数字。
import numpy as np
import time
max_number = 1000000000
# array for results
arr = np.zeros(max_number, dtype='int8')
# starting time
t0 = time.time()
# some tracking for the time spent
time_spent = []
# go through all possible numbers up to the larges possible factor
for p in range(2, int(np.sqrt(max_number))):
# if the number of factors for the number > 0, it is not a prime, jump to the next
if arr[p] > 0:
continue
# if we have a prime, we will have to go through all its powers < max_number
n = p
while n < max_number:
# increment the counter at n, 2n, 3n, ...
arr[n::n] += 1
# take the next power
n = n * p
# track the time spent
print "Time spent calculating the table of number of factors: {0} s".format(time.time()-t0)
# now we have the big primes left, but their powers are not needed any more
# they need to be taken into account up to max_number / 2
j = 0
for p in range(p + 1, (max_number + 1) / 2):
if arr[p] > 0:
continue
arr[p::p] += 1
if j % 10000 == 0:
print "{0} at {1} s".format(p, time.time()-t0)
j += 1
print "Primes up to {0} done at {1} s".format(p, time.time()-t0)
# now we have only big primes with no multiples left, they will be all 1
arr[arr == 0] = 1
print "Factor table done at {0} s".format(time.time() - t0)
# calculate the odd/even balance, note that 0 is not included and 1 has 0 factors
cumulative = np.cumsum(1 - 2 * (arr[1:] & 1), dtype='int32')
print "Total time {0} s".format(time.time()-t0)这不是最快也不是最优化的函数,这背后的数学应该是很明显的。在运行在一个核上的机器(i7)中,大约需要2800秒才能计算出多达1×10^9的素数因子的完整表(但请注意,如果没有64位python和至少8 GB,请不要尝试此操作)。累积和表消耗4GB。)
为了证明上面的函数至少运行得很好,下面是一个有趣区域的图:
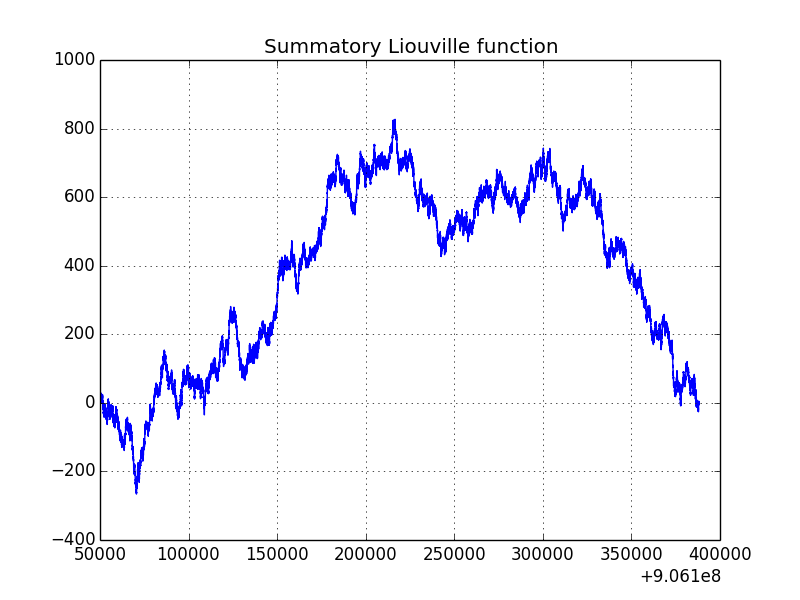
由于第一个数字的一些问题,上面的代码给出的结果稍微差一些。要获得官方的Liouville lambda,请使用cumulative[n-1] + 2。对于问题(906 316 571)中提到的数字,结果是cumulative[906316570] + 2等于829,这是该区域的最大值。
https://stackoverflow.com/questions/24586626
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号