
如何为人脸检测的最优方法指定弱分类器的阈值
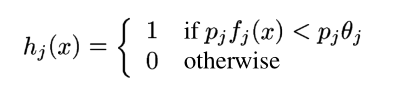
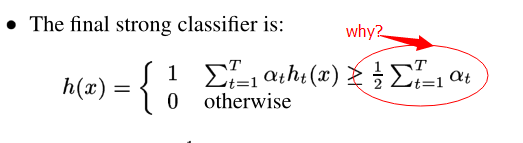
回答 2
Stack Overflow用户
发布于 2014-08-01 02:46:17
弱学习者计算各特征的参数theta_j。Viola和Jones的方法更好地记录在他们的2004年版他们的论文中,并且,IMHO非常类似于ROC分析。您必须针对训练集测试每个弱分类器,以寻找导致最小加权错误的theta_j。我们之所以说“加权”,是因为我们使用与每个训练样本相关的w_t,i值来对错误分类进行加权。
关于强分类器阈值的直观答案,请考虑所有的alpha_t = 1。这意味着至少应该有一半弱分类器输出1用于x,而强分类器输出1用于x。请记住,弱分类器输出1,如果它们认为x是face,而0则是face。
在Adaboost中,alpha_t可以被看作是对弱限定词质量的一种度量,即弱分类器所犯的错误越少,将会是。由于一些弱分类器比其他分类器更好,因此根据它们的质量来衡量他们的选票似乎是个好主意。强分类器的右手不等式反映出,如果权重加起来至少占所有权重的50%,则将x分类为1 (face)。
Stack Overflow用户
发布于 2014-06-26 21:28:32
您需要确定每个特性的theta_j。这是弱分类器的训练步骤。通常,找到最佳的theta_j取决于弱分类器的模型。在这种情况下,您需要检查这个特定特性对您的培训数据进行的所有值,并查看哪些值会导致最低的错误分类率。这将是你的theta_j。
https://stackoverflow.com/questions/24398614
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号