
matlab/倍频程-广义矩阵乘法
我想做一个推广矩阵乘法的函数。基本上,它应该能够做标准矩阵乘法,但它应该允许通过任何其他函数改变两个二进制运算符乘积/和。
目标是尽可能提高CPU和内存的效率。当然,它的效率总是低于A*B,但操作人员的灵活性才是重点。
下面是我在阅读五花八门 有意思的 线程之后可以使用的一些命令
A = randi(10, 2, 3);
B = randi(10, 3, 4);
% 1st method
C = sum(bsxfun(@mtimes, permute(A,[1 3 2]),permute(B,[3 2 1])), 3)
% Alternative: C = bsxfun(@(a,b) mtimes(a',b), A', permute(B, [1 3 2]))
% 2nd method
C = sum(bsxfun(@(a,b) a*b, permute(A,[1 3 2]),permute(B,[3 2 1])), 3)
% 3rd method (Octave-only)
C = sum(permute(A, [1 3 2]) .* permute(B, [3 2 1]), 3)
% 4th method (Octave-only): multiply nxm A with nx1xd B to create a nxmxd array
C = bsxfun(@(a, b) sum(times(a,b)), A', permute(B, [1 3 2]));
C = C2 = squeeze(C(1,:,:)); % sum and turn into mxd方法1-3的问题是,在使用sum()将其折叠之前,它们将生成n个矩阵。4是更好的,因为它在bsxfun中做了和(),但是bsxfun仍然生成n个矩阵(除了它们大多是空的,只包含一个非零值的向量是和,其余的填充0来满足维数的要求)。
我想要的是类似于第四种方法,但是没有多余的0来节省内存。
有什么想法吗?
回答 4
Stack Overflow用户
发布于 2014-06-24 16:37:39
下面是您发布的解决方案的稍微完善的版本,还有一些小的改进。
我们检查列是否比列多或相反,然后选择用矩阵乘行或用列乘矩阵(这样循环迭代次数最少),就可以相应地进行乘法。
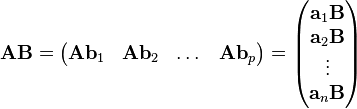
Note__:这可能并不总是最好的策略(按行而不是按列),即使列比列少;由于在内存中https://en.wikipedia.org/wiki/Row-major_order#Column-major_order中存储了MATLAB数组,因此按列切片更有效,因为元素是连续存储的。而访问行则涉及到通过https://en.wikipedia.org/wiki/Stride_of_an_array遍历元素(这对缓存不友好--比如https://en.wikipedia.org/wiki/Locality_of_reference)。
除此之外,代码应该处理双重/单一、真实/复杂、完全/稀疏(以及不可能组合的错误)。它还尊重空矩阵和零维数。
function C = my_mtimes(A, B, outFcn, inFcn)
% default arguments
if nargin < 4, inFcn = @times; end
if nargin < 3, outFcn = @sum; end
% check valid input
assert(ismatrix(A) && ismatrix(B), 'Inputs must be 2D matrices.');
assert(isequal(size(A,2),size(B,1)),'Inner matrix dimensions must agree.');
assert(isa(inFcn,'function_handle') && isa(outFcn,'function_handle'), ...
'Expecting function handles.')
% preallocate output matrix
M = size(A,1);
N = size(B,2);
if issparse(A)
args = {'like',A};
elseif issparse(B)
args = {'like',B};
else
args = {superiorfloat(A,B)};
end
C = zeros(M,N, args{:});
% compute matrix multiplication
% http://en.wikipedia.org/wiki/Matrix_multiplication#Inner_product
if M < N
% concatenation of products of row vectors with matrices
% A*B = [a_1*B ; a_2*B ; ... ; a_m*B]
for m=1:M
%C(m,:) = A(m,:) * B;
%C(m,:) = sum(bsxfun(@times, A(m,:)', B), 1);
C(m,:) = outFcn(bsxfun(inFcn, A(m,:)', B), 1);
end
else
% concatenation of products of matrices with column vectors
% A*B = [A*b_1 , A*b_2 , ... , A*b_n]
for n=1:N
%C(:,n) = A * B(:,n);
%C(:,n) = sum(bsxfun(@times, A, B(:,n)'), 2);
C(:,n) = outFcn(bsxfun(inFcn, A, B(:,n)'), 2);
end
end
end比较
毫无疑问,这个函数在整个过程中变慢了,但是对于较大的大小,它比内置的矩阵乘法差数量级:
(tic/toc times in seconds)
(tested in R2014a on Windows 8)
size mtimes my_mtimes
____ __________ _________
400 0.0026398 0.20282
600 0.012039 0.68471
800 0.014571 1.6922
1000 0.026645 3.5107
2000 0.20204 28.76
4000 1.5578 221.51
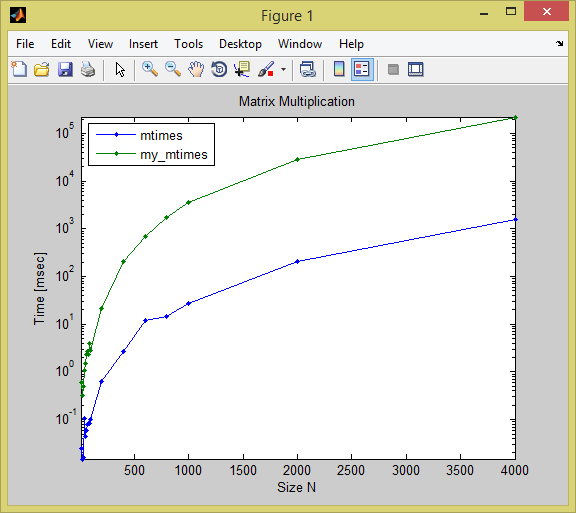
下面是测试代码:
sz = [10:10:100 200:200:1000 2000 4000];
t = zeros(numel(sz),2);
for i=1:numel(sz)
n = sz(i); disp(n)
A = rand(n,n);
B = rand(n,n);
tic
C = A*B;
t(i,1) = toc;
tic
D = my_mtimes(A,B);
t(i,2) = toc;
assert(norm(C-D) < 1e-6)
clear A B C D
end
semilogy(sz, t*1000, '.-')
legend({'mtimes','my_mtimes'}, 'Interpreter','none', 'Location','NorthWest')
xlabel('Size N'), ylabel('Time [msec]'), title('Matrix Multiplication')
axis tight额外的
为了完整起见,下面是实现广义矩阵乘法的两种简单的方法(如果您想比较性能,请用这两种方法替换my_mtimes函数的最后一部分)。我甚至不会费心地发布它们的运行时间:)
C = zeros(M,N, args{:});
for m=1:M
for n=1:N
%C(m,n) = A(m,:) * B(:,n);
%C(m,n) = sum(bsxfun(@times, A(m,:)', B(:,n)));
C(m,n) = outFcn(bsxfun(inFcn, A(m,:)', B(:,n)));
end
end另一种方法(使用三重循环):
C = zeros(M,N, args{:});
P = size(A,2); % = size(B,1);
for m=1:M
for n=1:N
for p=1:P
%C(m,n) = C(m,n) + A(m,p)*B(p,n);
%C(m,n) = plus(C(m,n), times(A(m,p),B(p,n)));
C(m,n) = outFcn([C(m,n) inFcn(A(m,p),B(p,n))]);
end
end
end接下来要尝试什么?
如果你想挤出更多的性能,你将不得不移动到一个C/C++ MEX文件,以减少解释的MATLAB代码的开销。您仍然可以利用优化的BLAS/LAPACK例程,从MEX文件中调用它们(参见本文的第二部分中的一个例子)。MATLAB附带了英特尔MKL库,坦率地说,当涉及到英特尔处理器上的线性代数计算时,这是无法比拟的。
其他人已经提到了一些文件交换的提交文件,这些文件将通用的矩阵例程实现为MEX-文件(见@natan的答案),如果您将它们与优化的BLAS库链接起来,它们尤其有效。
Stack Overflow用户
发布于 2014-06-21 17:01:16
为什么不利用bsxfun接受任意函数的能力呢?
C = shiftdim(feval(f, (bsxfun(g, A.', permute(B,[1 3 2])))), 1);这里
f是外函数(与矩阵乘法中的和相对应).它应该接受任意大小的mxnxp三维数组,并沿其列操作以返回1xmxp数组。g是内函数(对应于矩阵乘法中的乘积).根据bsxfun,它应该接受两个相同大小的列向量或一个列向量和一个标量作为输入,并作为输出返回与输入相同大小的列向量。
这是在Matlab中实现的。我还没在八达通测试过。
示例1:矩阵-乘法:
>> f = @sum; %// outer function: sum
>> g = @times; %// inner function: product
>> A = [1 2 3; 4 5 6];
>> B = [10 11; -12 -13; 14 15];
>> C = shiftdim(feval(f, (bsxfun(g, A.', permute(B,[1 3 2])))), 1)
C =
28 30
64 69检查:
>> A*B
ans =
28 30
64 69示例2:考虑以下两个矩阵
>> f = @(x,y) sum(abs(x)); %// outer function: sum of absolute values
>> g = @(x,y) max(x./y, y./x); %// inner function: "symmetric" ratio
>> C = shiftdim(feval(f, (bsxfun(g, A.', permute(B,[1 3 2])))), 1)
C =
14.8333 16.1538
5.2500 5.6346检查:手动计算C(1,2)
>> sum(abs( max( (A(1,:))./(B(:,2)).', (B(:,2)).'./(A(1,:)) ) ))
ans =
16.1538https://stackoverflow.com/questions/24245225
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号