
导入csv文件数据以填充Prolog知识库
导入csv文件数据以填充Prolog知识库
提问于 2014-06-07 07:52:32
我有一个csv文件example.csv,其中包含有头var1和var2的两列。
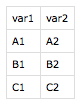
我想用重复的事实填充一个最初空的Prolog知识库文件import.pl,同时对每一行example.csv进行相同的处理:
fact(A1, A2).
fact(B1, B2).
fact(C1, C2).我如何在中编写这个代码呢?
编辑,基于@Shevliaskovic的答案
:- use_module(library(csv)).
import:-
csv_read_file('example.csv', Data, [functor(fact), separator(0';)]),
maplist(assert, Data).当import.在控制台中运行时,我们将按照请求的方式更新知识库(除了知识库在内存中直接更新,而不是通过文件和后续的查询)。
检查setof([X, Y], fact(X,Y), Z).:
Z = [['A1', 'A2'], ['B1', 'B2'], ['C1', 'C2'], [var1, var2]].回答 1
Stack Overflow用户
回答已采纳
发布于 2014-06-07 08:00:02
SWI有一个内置的过程。
它是
csv_read_file(+File, -Rows) 或者您可以添加一些选项:
csv_read_file(+File, -Rows, +Options) 你可以在文档上看到它。了解更多信息
以下是文档所包含的示例:
假设我们想要从CSV文件中创建一个谓词表/6,我们知道CSV文件每个记录包含6个字段。这可以使用下面的代码来完成。如果没有选项性(6),这将生成一个谓词表/N,其中N是数据中每个记录的字段数。
?- csv_read_file(File, Rows, [functor(table), arity(6)]),
maplist(assert, Rows).例如,:
如果您有一个File.csv,其外观如下:
A1 A2
B1 B2
C1 C2您可以像这样将它导入SWI:
9 ?- csv_read_file('File.csv', Data).其结果将是:
Data = [row('A1', 'A2'), row('B1', 'B2'), row('C1', 'C2')].页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/24095068
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号