
独立子句边界消歧和独立子句分段--有什么工具可以这样做吗?
我记得很久以前在NLTK网站上浏览过句子切分部分。
我使用粗体文本将“句点”“空格”替换为“句点”“手动行中断”,以实现句子分段,例如使用Microsoft替换(. -> .^p)或Chrome扩展:
https://github.com/AhmadHassanAwan/Sentence-Segmentation
https://chrome.google.com/webstore/detail/sentence-segmenter/jfbhkblbhhigbgdnijncccdndhbflcha
这不是像NLTK的Punkt令牌器那样的NLP方法。
我分片帮助我更容易地找到和重读句子,这有时有助于阅读理解。
那么独立子句边界消歧和独立子句分割又如何呢?是否有任何工具试图做到这一点?
下面是一些示例文本。如果一个独立的子句可以在一个句子中被识别,那么就会有一个分裂。从句子的结尾开始,它向左移动,贪婪地分裂:
例如。
语句边界消歧是自然语言处理中的一个问题,也被称为断句。 句子开始和结束。 通常是,自然语言处理工具 由于一些原因,要求他们的输入被分成几个句子。 然而,句子边界识别是很有挑战性的,因为标点符号 标记通常是模棱两可的。 对于示例来说,一个句点可能 表示缩写、小数点、省略号或电子邮件地址--而不是句子的结尾。 “华尔街日报”语料库中47%的关于 表示缩写。 As好,问号和感叹号可以 出现在嵌入的引号、表情符号、计算机代码和俚语中。 另一种方法是自动 从句子所在的一组文档中学习一套规则 断点是预先标记的。 语言喜欢日语和汉语 有明确的句号结束标记。 标准的“香草”方法 找出句子的结尾: (a) If 它是句号,它结束了一个句子。 (b) 如果前面的标记在我手工编辑的缩略语列表中,那么它不会结束一个句子。 (c) 如果下一个令牌是大写的,那么它就结束一个句子。 这个 策略得到约95%的句子正确 解决方案基于最大熵模型。 The SATZ体系结构使用神经网络 消除歧义,准确率达98.5%。
(我不确定我是否正确地分配了它。)
如果没有方法分割独立子句,我是否可以使用任何搜索词来进一步探讨这个主题?
谢谢。
回答 5
Stack Overflow用户
发布于 2014-05-25 21:13:23
据我所知,没有现成的工具来解决这个确切的问题。通常情况下,NLP系统不会涉及到英语语法定义的不同类型的句子和从句的识别问题。在EMNLP中发表了一篇论文,该论文提供了一种算法,使用解析树中的SBAR标记来识别句子中的独立和从属子句。
您应该会发现本文第三节很有用。它谈到了一些细节的英语语言语法,但我认为整篇论文与你的问题无关。
请注意,他们使用了伯克利解析器(可在这里获得演示),但是您显然可以使用任何其他的选区解析工具(例如斯坦福解析器可在这里获得演示)。
Stack Overflow用户
发布于 2015-10-06 20:25:17
Chthonic项目在这里提供了一些很好的信息:
部分答案是:
如果您主要使用基于组的解析树,而不是依赖项,可能会更好。 子句由SBAR标记指示,它是由(可能为空的)从属连词引入的子句。 您所需要做的就是:
- 识别解析树中的非根式节点。
- 从主树中移除(但单独保留)根植于这些分节节的子树。
- 在主树中(在第二步移除子树之后),删除任何悬挂介词、从属连词和副词。
有关所有子句标记的列表(以及,实际上,所有宾夕法尼亚树银行标记),请参见以下列表:http://www.surdeanu.info/mihai/teaching/ista555-fall13/readings/PennTreebankConstituents.html
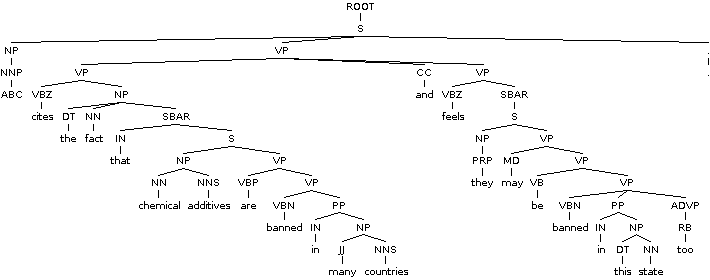
对于联机解析树可视化,您可能需要使用在线伯克利解析器演示。
它对形成更好的直觉有很大帮助。
下面是为例句生成的图像:
Stack Overflow用户
发布于 2017-08-26 01:42:51
我不知道有什么工具可以做分句,但在修辞结构理论中,有一种叫做“基本语篇单位”的概念,它的作用方式类似于一个从句。然而,它们有时比条款略小。
有关此概念的更多信息,请参阅本手册第2.0节:
https://www.isi.edu/~marcu/discourse/tagging-ref-manual.pdf
有一些在线软件可以将句子分割成基本的话语单元,例如:
http://alt.qcri.org/tools/discourse-parser/
和
https://stackoverflow.com/questions/23859892
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号