
Weka中“混淆矩阵”的混淆
我在LingSpam数据集上运行支持向量机分类器,并在WEKA中得到以下混淆矩阵:
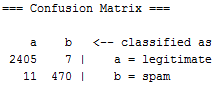
如果我们考虑合法的->正类和垃圾邮件->负面类,那么True Positives=2405和True Negatives=470。
但我对假阴性和假阳性感到困惑。如果你读了“困惑表”部分这里,它看起来像是假的Positives=11和假的Negatives=7。但是如果你读了这里 (请使用Ctrl+F并搜索‘所有这些数字意味着什么?’),它似乎是假的Positives=7和假的Negatives=11。
我很困惑:请帮帮我!此外,IR_Precision和IR_Recall在WEKA中是什么?是legitimate_precision和legitimate_recall还是spam_precision和spam_recall?
注:将合法电子邮件视为积极类,将垃圾邮件视为负面类。
回答 2
Stack Overflow用户
发布于 2014-05-21 07:09:24
这取决于您定义的“积极”类是什么。“合法”没有什么特别之处,这意味着它是一个积极的类,你可以用任何一种方式去做。
在这里将“垃圾邮件”称为积极类会更加传统,因为这是您正在检测到的不寻常属性。在这种解释中,有470个真正的积极因素,等等,在你的解释中,有2405个。这两种方法本身都是错误的,但同样地,将“垃圾邮件”作为积极类来对待可能是一种习惯。
同样的答案是关于精确性和召回。它适用于正类,但取决于您所使用的正类。如果你在这个混乱的矩阵,它将寻找精确性和召回的“合法”作为积极的类。理想情况下,我会扭转这种局面。
Stack Overflow用户
发布于 2014-05-29 20:52:23
首先,如果你仔细看一下关于垃圾邮件分类问题的研究文章,几乎所有的文章都把垃圾邮件定义为正数,把垃圾邮件定义为否定词。在你的情况下,情况正好相反。所以,它有机会混淆读者。
然而,Weka混淆矩阵是完全可以的。以下是根据传统垃圾邮件分类任务对正反两类的定义:
True positives: original label spam, predicted label spam (very good)
False positives: original label ham, predicted label spam (very dangerous)
False negatives: original label spam, predicted label ham (less dangerous)
True negatives: original label hams, predicted labels ham (very good)在您的情况下(如果您想要与传统垃圾邮件分类任务中的内容进行比较),
True positives: 470
False positives: 7
False negatives: 11
True negatives: 2405只要把混乱矩阵颠倒过来就可以这样解读它们了。我认为主要的困惑来自于你对积极和消极的定义。
希望这能有所帮助。
https://stackoverflow.com/questions/23775669
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号