
在将.ods文件转换为.csv文件时替换或忽略新的行字符
我使用Gnumeric中的ssconvert命令将一组ODS文件转换为CSV文件:
ssconvert -O 'separator=; quoting-mode=never' "f.ods" "f.txt";
效果很好。大多数时候都是。有时,用户在单元格中插入一个新行字符的单元格(在Mac上的OpenOffice和LibreOffice中,您可以通过按cmd+enter来实现这一点)。这将导致随后创建的CSV文件获得一个额外的行,因此而不是
This is some text. Here comes a newline that should be ignored;Some data;Some more data
我得到了
This is some text. Here comes a newline that should be ignored;Some data; Some more data
在转换过程中,是否可以将单元格中的所有换行符替换为其他字符,例如*
或者,我可以将计算机设置为忽略单元格中的所有内联字符吗?
回答 2
Stack Overflow用户
发布于 2014-06-27 18:09:16
你的问题是:
ssconvert -O 'separator=;quoting-mode=never'"f.ods" "f.txt";
如果必要的话,通过阻止ssconvert引用,您就会在这里开枪,而您的问题并不局限于换行符。例如,这个电子表格:
example.ods
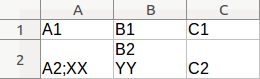
由ssconvert命令转换为:
example.txt
A1;B1;C1
A2;XX;B2
YY;C2祝你好运解开它。
与其试图在转换后消除混乱(这是不可能可靠的),也不是通过在转换之前对源ODS文件进行某种方式的预处理(这太疯狂了--如果您要转换为CSV --这大概是因为您想避免干扰ODS文档),您需要使用没有这种根本缺陷的CSV方言。
这意味着你需要你的数据被引用。事实证明,ssconvert不足以引用默认设置中包含分隔符的单元格:
$ ssconvert -O 'separator=;' example.ods example-2.txt
$ cat example-2.txt
A1;B1;C1
A2;XX;"B2
YY";C2..。所以你需要引用所有的话:
$ ssconvert -O 'separator=; quoting-mode=always' example.ods example-3.txt
$ cat example-3.txt
"A1";"B1";"C1"
"A2;XX";"B2
YY";"C2"在CSV中没有可靠的解决方案;除了正确引用数据之外,您想出的任何解决方案都会在某个时候回来并咬你一口,因为未引用的CSV作为一种数据格式从根本上被打破了。
重申:不试图解决未引用的CSV中的这一基本缺陷。即使您认为您已经解决了使用模糊数据格式为自己创建的所有问题,但在某一时刻,您没有预料到的情况会出现,而且您会在空闲时后悔。
Stack Overflow用户
发布于 2022-08-10 15:57:28
另一种解决方案(在本例中用于xlsx文件)是:
- (如果尚未安装)安装
xlsx2csv:apt或pip安装
- 使用选项
-e,在多行单元格内,换行符将被\n替换。
重复使用@ZeroPiraeus的例子
$ xlsx2csv -e -d ';' example.xlsx
A1;B1;C1
A2;XX;B2\nYY;C2https://stackoverflow.com/questions/23681880
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号