
JSoup与Wunderground数据
JSoup与Wunderground数据
提问于 2014-05-14 19:03:47
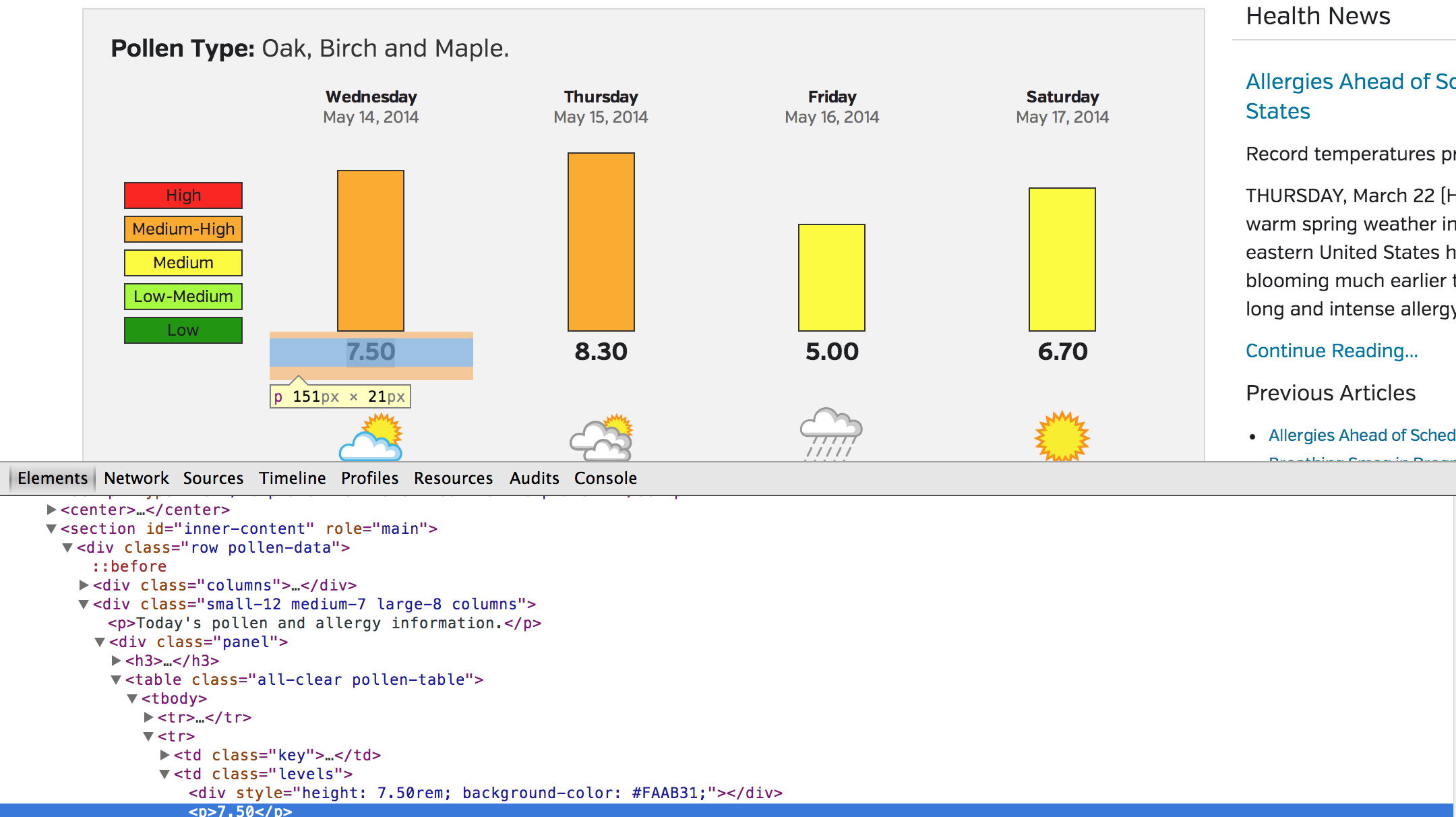
我目前正在从wunderground抓取花粉数据,因为他们的API访问器不提供花粉数据,特别是归因于每天的值。
我已经使用Chrome工具导航了HTML,并找到了我想要的具体行。使用文档提供的JSoup,我尝试了自己的自定义CSS选择器,但我是完全迷路了。
我想知道是否有人会给我一些关于如何访问特定元素的洞察力。
例如,下面是我到目前为止所得到的一个例子。
doc = Jsoup.connect("http://www.wunderground.com/DisplayPollen.asp?Zipcode=19104").get();
Element title = doc.getElementById("td");
Element tagName = doc.tagName("id");
System.out.println(tagName);
回答 2
Stack Overflow用户
回答已采纳
发布于 2014-05-14 19:24:34
您不想使用doc.getElementById("td"),因为<td>不是id属性,而是标记( getElementById也不支持CSS查询)。
您想要的是select first <td>和levels类。你可以通过
Element tag = doc.select("td.levels").first();此外,为了只获取将使用此标记(而不是整个HTML)生成的文本,请使用text()方法,如下
System.out.println(tag.text());Stack Overflow用户
发布于 2014-05-14 19:35:14
Document doc = Jsoup.connect("http://www.wunderground.com/DisplayPollen.asp?Zipcode=19104").get();
Elements days = doc.select("table.pollen-table").first().select("td.even-four");
for (Element day : days) {
System.out.println(day.text());
}
Elements levels = doc.select("td.levels");
for (Element level : levels) {
System.out.println(level.text());
}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/23663012
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号