
用于不同语言URL的Preg_match
用于不同语言URL的Preg_match
提问于 2014-04-22 13:48:49
我有这样的短信:
$text = "Some thing is there http://example.com/جميع-وظائف-فى-السليمانية
http://www.example.com/جميع-وظائف-فى-السليمانية nothing is there
Check me http://example.com/test/for_me first
testing http://www.example.com/test/for_me the url
Should be test http://www.example.com/翻译-英语教师-中文教师-外贸跟单
simple text";我需要preg_match的网址,但他们是不同的语言。
所以,我需要得到URL本身,从每一行。
我是这样做的:
$text = preg_replace("/[\n]/", " <br>", $text);
$lines = explode("<br>", $text);
foreach($line as $textLine){
if (preg_match("/(http\:\/\/(.*))/", $textLine, $match )) {
// some code
// Here I need the url
}
}我现在的标准是/(http\:\/\/(.*))/,请建议我如何使它与不同语言中的URL兼容?
回答 2
Stack Overflow用户
回答已采纳
发布于 2014-04-22 14:07:03
像这样的正则表达式可能对您有用吗?
在我的测试中,它适用于您给出的文本示例,但是它并不是很高级。它将简单地选择http://或https://之后的所有字符,直到出现空白字符(空格、新行、制表符等)。
/(https?\:\/\/(?:[^\s]+))/gi
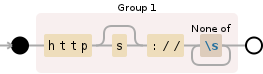
下面是示例字符串匹配内容的可视化示例:
http://regex101.com/r/bR0yE9
Stack Overflow用户
发布于 2014-04-22 14:08:28
您不需要逐行工作,您可以直接搜索:
if (preg_match_all('~\bhttp://\S+~', $text, $matches))
print_r($matches);其中\S的意思是“这一切都不是白字”。
没有什么特殊的内化问题。
注意:如果您想用<br/>替换所有新行,我建议使用$text = preg_replace('~\R~', '<br/>', $text);,因为当\n只匹配unix时,\R处理几种类型的换行符。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/23221483
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号