
将HTML解析为父-子对象C#
将HTML解析为父-子对象C#
提问于 2014-04-11 14:42:13
我正在解析html页面,而且我对这类解析还不熟悉,您能建议我按照html来解析吗?
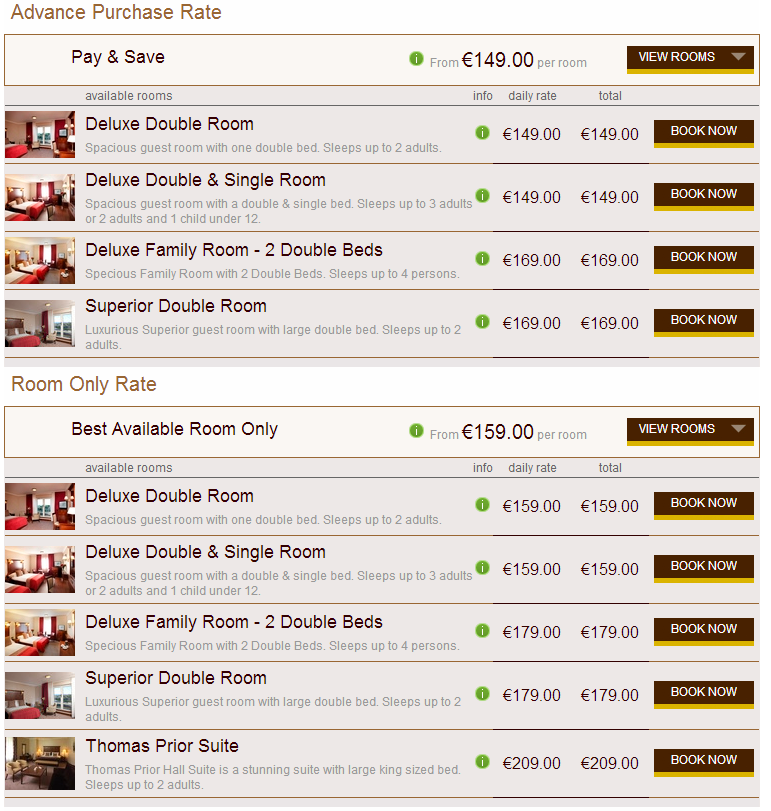
HTML:http://notepad.cc/share/CFRURbrk3r
对于每种类型的房间,都有子房间的列表,因此我希望将它们分组为对象列表中的父-子-子。然后,我们可以访问每一个孩子。
这是我所能做的代码,但是没有添加到对象中,除了Fizzler,在本例中还有其他解析器可以完成。
var uricontent = File.ReadAllText("TestHtml/Bew.html");
var html = new HtmlDocument(); // with HTML Agility pack
html.LoadHtml(uricontent);
var doc = html.DocumentNode;
var rooms = (from r in doc.QuerySelectorAll(".rates")
from s in r.QuerySelectorAll(".rooms")
from rd in r.QuerySelectorAll(".rate")
select new
{
Name = rd.QuerySelector(".rate-description").InnerText.CleanInnerText(),
Price = r.QuerySelector(".rate-price").InnerText.CleanInnerText(),
RoomType = s.QuerySelector("tr td h2").InnerText.CleanInnerText()
}).ToArray(); 回答 1
Stack Overflow用户
回答已采纳
发布于 2014-04-11 15:00:25
更新:
就我个人而言,我不会使用数组。我会用List。List的实现应该允许您将特定的节点添加到特定的位置并进行相应的分组。
然后你就可以简单地:
- 回路(前缘)
- 发现
- 排序
- 选择
这将允许您快速过滤内容。因为每个列表项都是存储的。一些示例。
更新:
我忘记提到的另一项内容是,Html敏捷包可以执行以下操作:
- 抓取特定的节点/元素。
- 获取父节点和所有后续的子节点/元素。
它还可以抓取远程或本地页面。
我实际上会从Nuget下载Html敏捷包。它非常强大和健壮,它更有可能使对所需数据的清除变得更加容易。您可以通过以下步骤下载它:
- 使用工具
- 转到Nuget包装经理
- 选择控制台
- 如果软件包管理器控制台没有打开,则在Visual的左下角打开它。
- 键入以下命令
Install-Package HtmlAgilityPack。
从这个问题中可以找到一个很好的例子。
前提很简单:
HtmlAgilityPack.HtmlDocument document = new HtmlAgilityPack.HtmlDocument();
// Map the document to the Html Page.
document.Load(filePath);
// If you would rather do it through Xml String, should you require it.
if (document.DocumentNode != null)
{
HtmlAgilityPack.HtmlNode bodyNode = htmlDoc.DocumentNode.SelectSingleNode("//body");
if( bodyNode != null)
{
// Do something with bodyNode.
}
}这个例子显示了语法,但是从页面中抓取特定的节点并相应地使用HtmlAgilityPack操作应该要容易得多。
希望这能为你指明一个更好的方向。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/23015735
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号