
算术编码器的优化
我正在优化名为C++的PackJPG库的编码步骤
我用Intel VTune对代码进行了描述,发现当前的瓶颈是PackJPG使用的算术编码器中的以下函数:
void aricoder::encode( symbol* s )
{
// update steps, low count, high count
unsigned int delta_plus_one = ((chigh - clow) + 1);
cstep = delta_plus_one / s->scale;
chigh = clow + ( cstep * s->high_count ) - 1;
clow = clow + ( cstep * s->low_count );
// e3 scaling is performed for speed and to avoid underflows
// if both, low and high are either in the lower half or in the higher half
// one bit can be safely shifted out
while ( ( clow >= CODER_LIMIT050 ) || ( chigh < CODER_LIMIT050 ) ) {
if ( chigh < CODER_LIMIT050 ) { // this means both, high and low are below, and 0 can be safely shifted out
// write 0 bit
write_zero();
// shift out remaing e3 bits
write_nrbits_as_one();
}
else { // if the first wasn't the case, it's clow >= CODER_LIMIT050
// write 1 bit
write_one();
clow &= CODER_LIMIT050 - 1;
chigh &= CODER_LIMIT050 - 1;
// shift out remaing e3 bits
write_nrbits_as_zeros();
}
clow <<= 1;
chigh = (chigh << 1) | 1;
}
// e3 scaling, to make sure that theres enough space between low and high
while ( ( clow >= CODER_LIMIT025 ) && ( chigh < CODER_LIMIT075 ) ) {
++nrbits;
clow &= CODER_LIMIT025 - 1;
chigh ^= CODER_LIMIT025 + CODER_LIMIT050;
// clow -= CODER_LIMIT025;
// chigh -= CODER_LIMIT025;
clow <<= 1;
chigh = (chigh << 1) | 1;
}
}这个函数似乎借用了:http://paginas.fe.up.pt/~vinhoza/itpa/bodden-07-arithmetic-TR.pdf的一些想法。我已经在一定程度上优化了这个函数(主要是通过加快编写的速度),但现在我陷入了困境。
目前最大的瓶颈似乎是一开始的分裂。这个来自VTune的屏幕截图显示了结果所需的时间以及创建的程序集(右边的蓝色程序集对应于选择到左侧的源代码中的行)。
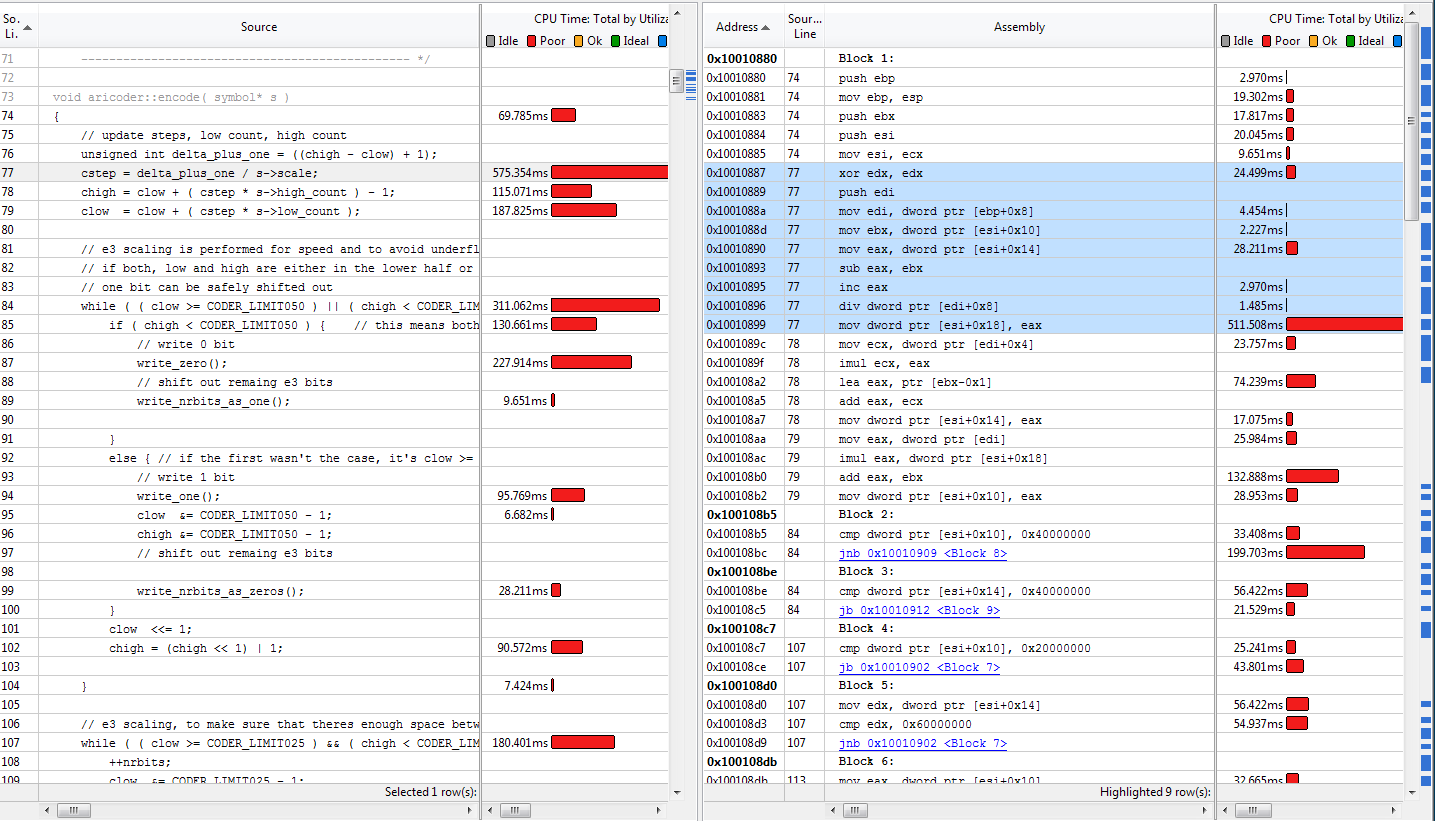
S->比例尺不一定是2的偶数幂,因此不能用模运算代替除法。
代码是用MSVC编译的(来自Visual 2013),设置如下:
/GS /Qpar- /GL /analyze- /W3 /Gy- /Zc:wchar_t /Zi /Gm- /Ox /sdl /Fd"Release\vc120.pdb" /fp:precise /D "WIN32" /D "NDEBUG" /D "_WINDOWS" /D "_USRDLL" /D "PACKJPG_EXPORTS" /D "_CRT_SECURE_NO_WARNINGS" /D "BUILD_DLL" /D "_WINDLL" /D "_UNICODE" /D "UNICODE" /errorReport:prompt /WX- /Zc:forScope /arch:IA32 /Gd /Oy- /Oi /MT /Fa"Release\" /EHsc /nologo /Fo"Release\" /Ot /Fp"Release\PackJPG.pch" 关于如何进一步优化这一点,有什么想法吗?
更新1 --到目前为止,我已经尝试了所有的建议--这是现在最快的版本:
void aricoder::encode( symbol* s )
{
unsigned int clow_copy = clow;
unsigned int chigh_copy = chigh;
// update steps, low count, high count
unsigned int delta_plus_one = ((chigh_copy - clow_copy) + 1);
unsigned register int cstep = delta_plus_one / s->scale;
chigh_copy = clow_copy + (cstep * s->high_count) - 1;
clow_copy = clow_copy + (cstep * s->low_count);
// e3 scaling is performed for speed and to avoid underflows
// if both, low and high are either in the lower half or in the higher half
// one bit can be safely shifted out
while ((clow_copy >= CODER_LIMIT050) || (chigh_copy < CODER_LIMIT050)) {
if (chigh_copy < CODER_LIMIT050) { // this means both, high and low are below, and 0 can be safely shifted out
// write 0 bit
write_zero();
// shift out remaing e3 bits
write_nrbits_as_one();
}
else { // if the first wasn't the case, it's clow >= CODER_LIMIT050
// write 1 bit
write_one();
clow_copy &= CODER_LIMIT050 - 1;
chigh_copy &= CODER_LIMIT050 - 1;
// shift out remaing e3 bits
write_nrbits_as_zeros();
}
clow_copy <<= 1;
chigh_copy = (chigh_copy << 1) | 1;
}
// e3 scaling, to make sure that theres enough space between low and high
while ((clow_copy >= CODER_LIMIT025) & (chigh_copy < CODER_LIMIT075)){
++nrbits;
clow_copy &= CODER_LIMIT025 - 1;
chigh_copy ^= CODER_LIMIT025 + CODER_LIMIT050;
// clow -= CODER_LIMIT025;
// chigh -= CODER_LIMIT025;
clow_copy <<= 1;
chigh_copy = (chigh_copy << 1) | 1;
}
clow = clow_copy;
chigh = chigh_copy;
}下面是使用此版本更新的VTune结果:
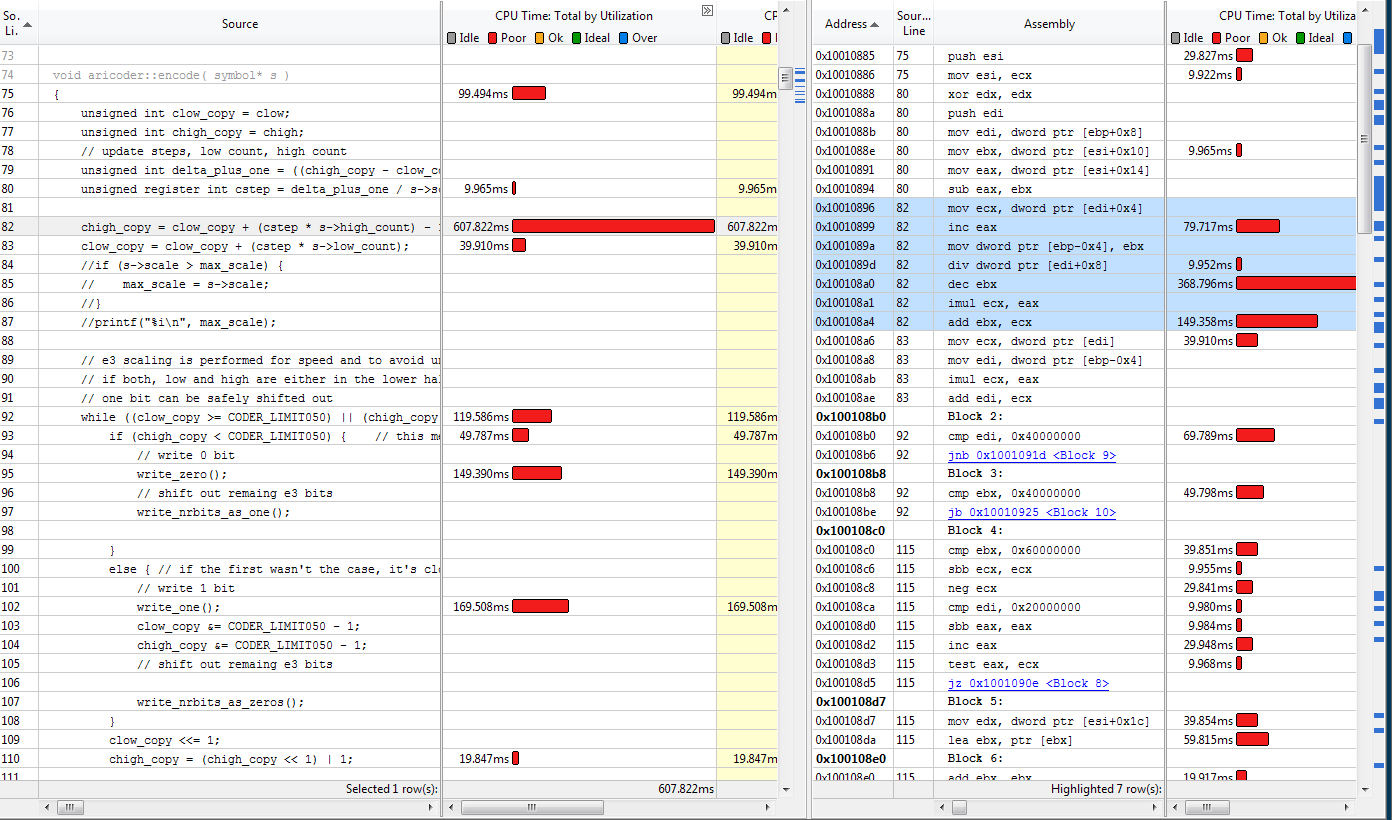
这个新版本包括以下修改:
- 通过在最后一个while循环中使用&而不是&&来避免一个分支(这个技巧在第一个循环中没有帮助)。
- 将类字段复制到局部变量。
不幸的是,下面的建议是而不是提高了性能:
- 将第一个while循环替换为用goto语句的开关。
- 使用不动点算法进行除法(它会产生舍入误差)。
- 做一个s->比例的开关和做位移位,而不是除法2的偶数.
@示例表明,不是分割速度慢,而是分区的操作数之一的内存访问。这似乎是正确的。根据VTune的说法,我们经常在这里错过缓存。对如何解决这个问题有什么建议吗?
回答 3
Stack Overflow用户
发布于 2014-04-19 15:49:35
根据VTune的说法,我们经常在这里错过缓存。对如何解决这个问题有什么建议吗?
我们组织数据的方式直接影响到作为数据局部性的性能,因此缓存机制的行为取决于此。因此,为了实现这一点,我们的程序应该尽可能多地进行线性内存访问,并且应该避免任何间接的内存读写(基于指针的数据结构)。这将真正受到缓存机制的喜爱,因为拥有L1缓存的内存的概率将显著提高。
在查看代码和VTune报告时,看起来最重要的数据是传递给这个特定函数的参数。这个对象的各种数据成员正在这个特定函数中被使用(内存读取)。
void aricoder::encode( symbol* s )下面是程序访问该对象的数据成员的代码:
s->scale
s->high_count
s->low_count从这两个VTune报告中,我们可以验证所有三个内存访问都有不同的时间。这表明这些数据在此特定对象的不同偏移量处。在访问them(s->high_count),缓存时,它将从L1缓存中退出,因此需要花费更多的时间,因为它必须将数据带到缓存中。正因为如此,s->low_正在受益,因为它现在在L1缓存中。根据这些数据,我可以想到以下几点:
- 将访问最多的数据成员放入对象内的热点区域。这意味着我们应该将所有这些成员放在对象的第一个/顶部。通过这种方式,我们将更有可能使我们的对象符合对象的第一个缓存行。因此,我们应该尝试按照对象的数据成员访问来重新组织对象内存布局。我假设您没有处理这个对象中的虚拟表,因为从缓存机制来看,它们不是很好。
- 您的整个程序的组织方式有可能是围绕这一点(.i.e执行此函数),L1缓存是满的,因此程序试图从L2和这个转换访问它,将会有更多的CPU周期(尖峰)。在这种情况下,我不认为我们可以做太多,因为这是某种程度上的机器限制,从某种意义上说,我们正在扩大我们的边界太多,试图处理太低水平的东西。
- 您的对象的似乎是过氧化物酶的类型,因此会有线性访问。这是好的,没有改进的余地。然而,我们分配的方式可能会对缓存机制产生影响。如果每次都要分配,则在当前函数中执行时会产生影响。
除此之外,我认为我们还应该参考下面的文章,其中详细讨论了这些概念(数据缓存/指令缓存)。这些帖子也有很好的链接,对此有深入的分析和信息.
我建议,你应该试着把这些帖子转过来。它们对于理解这些概念的内部结构确实很有帮助,尽管这可能无助于优化当前的代码。也许你的程序已经被优化了,在这方面我们几乎无能为力:)。
Stack Overflow用户
发布于 2014-04-10 19:06:44
这不是完整的答案。此代码演示了使用不动点算法执行快速整数除法。广泛应用于DSP和信号处理中。注意,只有当“缩放”更改不频繁时,代码才有意义进行优化。此外,在“比例”值较小的情况下,可以重写代码以使用uint32_t作为中间结果。
#include <stdio.h>
#include <stdint.h>
int main(int argc, char **argv)
{
uint32_t scale;
uint32_t scale_inv;
uint32_t delta_plus_one;
uint32_t val0, val1;
uint64_t tmp;
scale = 5;
delta_plus_one = 44533;
/* Place the line in 'scale' setter function */
scale_inv = 0x80000000 / scale;
/* Original expression */
val0 = (delta_plus_one / scale);
/* Division using multiplication uint64_t by uint32_t,
using uint64_t as intermediate result */
tmp = (uint64_t)(delta_plus_one) * scale_inv;
/* shift right to produce result */
val1 = tmp >> 31;
printf("val0 = %u; val1 = %u\n", val0, val1);
return 0;
}Stack Overflow用户
发布于 2014-04-10 16:18:59
从CODER_LIMIT050开始是一个愚蠢的名字,CODER_LIMIT025和CODER_LIMIT075的共存使它变得特别愚蠢。除此之外,如果不存在任何副作用,则可能不希望使用短路逻辑,所以第二个while语句可以是:
while ( ( clow >= CODER_LIMIT025 ) & ( chigh < CODER_LIMIT075 ) )第一个while块可以进一步优化,以便将每次迭代的3个可能的分支语句折叠为一个:
start:
switch ( ( clow >= CODER_LIMIT050 ) | (( chigh < CODER_LIMIT050 )<<1) )
{
default: break;
case 1:
write_zero ( );
write_nrbits_as_one ( );
clow <<= 1;
chigh = ( chigh << 1 ) | 1;
goto start;
case 3: // think about this case, is this what you want?
case 2:
write_one ( );
clow &= CODER_LIMIT050 - 1;
chigh &= CODER_LIMIT050 - 1;
write_nrbits_as_zeros ( );
clow <<= 1;
chigh = ( chigh << 1 ) | 1;
goto start;
}如果你想通过s->scale优化除法,问问自己它到底有多大的变数?如果只有少数几种可能的情况,那么将其模板化。一旦它是编译时间常数,编译器可以尝试找到位移位(如果可能的话),或者在伽罗瓦域GF(4294967296)中找到它的乘法逆(如果有)。
https://stackoverflow.com/questions/22991801
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号