
将PDF转换为图像(格式正确)
我有一个pdf文件(附件)。我的目标是像IT一样使用pdfbox将pdf转换成图像(就像在windows中使用狙击工具一样)。pdf有各种形状和文本。
我使用以下代码:
PDDocument doc = PDDocument.load("Hello World.pdf");
PDPage firstPage = (PDPage) doc.getDocumentCatalog().getAllPages().get(67);
BufferedImage bufferedImage = firstPage.convertToImage(imageType,screenResolution);
ImageIO.write(bufferedImage, "png",new File("out.png"));
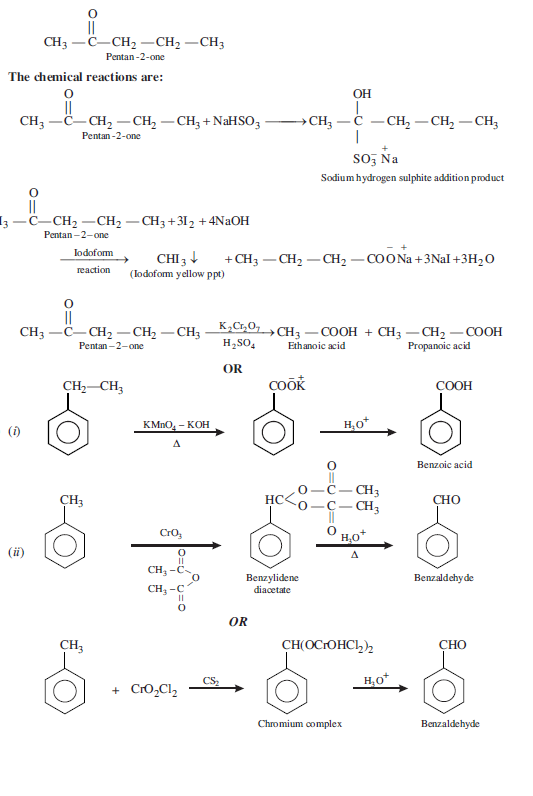
当我使用代码时,图像文件提供了完全错误的输出(附加了out.png)。
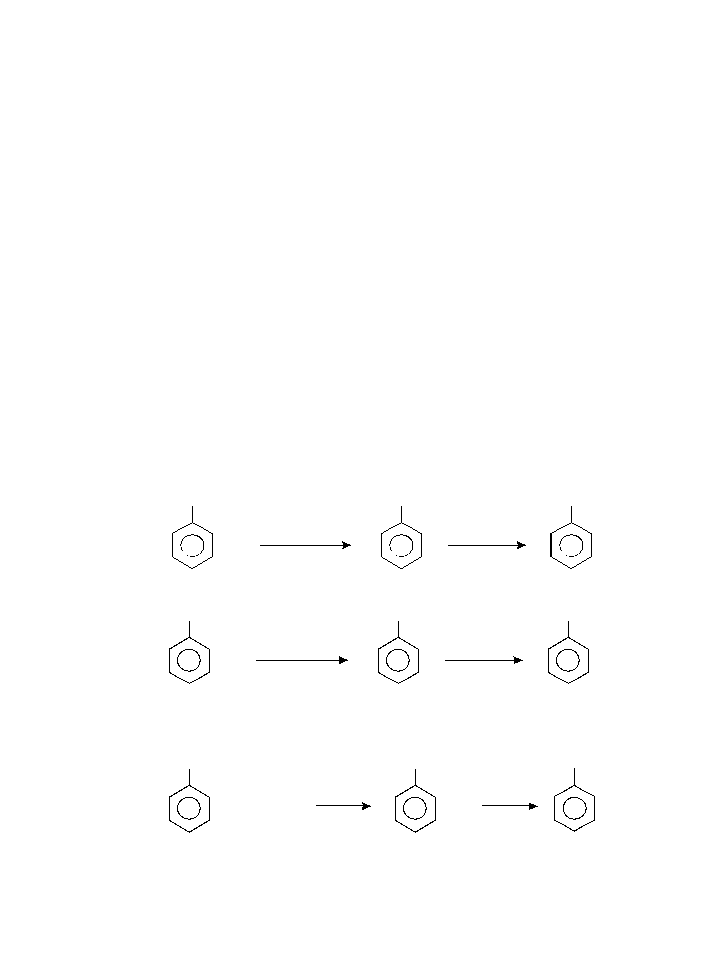
如何使pdfbox获取类似于直接快照图像的内容?
另外,我注意到png的图像质量不太好,有没有办法提高产生的图像的分辨率?
编辑:这是pdf(见第68页) https://drive.google.com/file/d/0B0ZiP71EQHz2NVZUcElvbFNreEU/edit?usp=sharing
编辑2:似乎所有的文本都在消失。我还尝试使用PDFImageWriter类
test.writeImage(doc, "png", null, 68, 69, "final.png",TYPE_USHORT_GRAY,200 );相同结果
回答 3
Stack Overflow用户
发布于 2014-03-14 06:41:29
事实证明,jpedal(lgpl)完美地完成了转换(就像快照一样)。
以下是我所用的:
PdfDecoder decode_pdf = new PdfDecoder(true);
FontMappings.setFontReplacements();
decode_pdf.openPdfFile("Hello World.pdf");
decode_pdf.setExtractionMode(0,800,3);
try {
for(int i=0;i<40;i++)
{
BufferedImage img=decode_pdf.getPageAsImage(2+i);
ImageIO.write(img, "png",new File(String.valueOf(i)+"out.png"));
}
} catch (IOException ex) {
Logger.getLogger(NewJFrame.class.getName()).log(Level.SEVERE, null, ex);
}
decode_pdf.closePdfFile();
} catch (PdfException e) {
e.printStackTrace();
}效果很好。
Stack Overflow用户
发布于 2014-03-13 11:23:34
使用PDFRenderer,可以将PDF页面转换成图像格式。
使用PDF渲染器将PDF页面转换为java中的图像。Jars需要PDFRenderer-0.9.0
package com.pdfrenderer.examples;
import java.awt.Graphics2D;
import java.awt.Image;
import java.awt.Rectangle;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import javax.imageio.ImageIO;
import com.sun.pdfview.PDFFile;
import com.sun.pdfview.PDFPage;
public class PdfToImage {
public static void main(String[] args) {
try {
String sourceDir = "C:/Documents/Chemistry.pdf";// PDF file must be placed in DataGet folder
String destinationDir = "C:/Documents/Converted/";//Converted PDF page saved in this folder
File sourceFile = new File(sourceDir);
File destinationFile = new File(destinationDir);
String fileName = sourceFile.getName().replace(".pdf", "_cover");
if (sourceFile.exists()) {
if (!destinationFile.exists()) {
destinationFile.mkdir();
System.out.println("Folder created in: "+ destinationFile.getCanonicalPath());
}
RandomAccessFile raf = new RandomAccessFile(sourceFile, "r");
FileChannel channel = raf.getChannel();
ByteBuffer buf = channel.map(FileChannel.MapMode.READ_ONLY, 0, channel.size());
PDFFile pdf = new PDFFile(buf);
int pageNumber = 62;// which PDF page to be convert
PDFPage page = pdf.getPage(pageNumber);
System.out.println("Total pages:"+ pdf.getNumPages());
// create the image
Rectangle rect = new Rectangle(0, 0, (int) page.getBBox().getWidth(), (int) page.getBBox().getHeight());
BufferedImage bufferedImage = new BufferedImage(rect.width, rect.height, BufferedImage.TYPE_INT_RGB);
// width & height, // clip rect, // null for the ImageObserver, // fill background with white, // block until drawing is done
Image image = page.getImage(rect.width, rect.height, rect, null, true, true );
Graphics2D bufImageGraphics = bufferedImage.createGraphics();
bufImageGraphics.drawImage(image, 0, 0, null);
File imageFile = new File( destinationDir + fileName +"_"+ pageNumber +".png" );// change file format here. Ex: .png, .jpg, .jpeg, .gif, .bmp
ImageIO.write(bufferedImage, "png", imageFile);
System.out.println(imageFile.getName() +" File created in: "+ destinationFile.getCanonicalPath());
} else {
System.err.println(sourceFile.getName() +" File not exists");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}ConvertedImage:
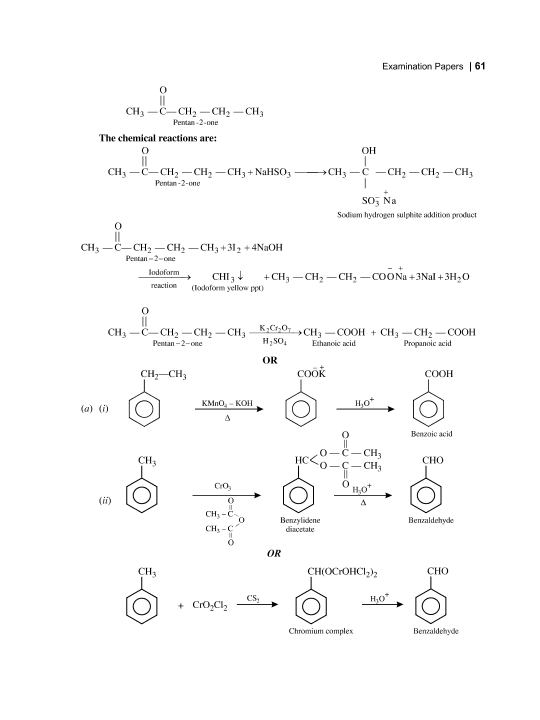
Stack Overflow用户
发布于 2014-03-12 16:43:21
我使用PDFBox版本1.8.4获得了与OP相同的结果。不过,在版本2.0.0-快照中,它看起来更好:
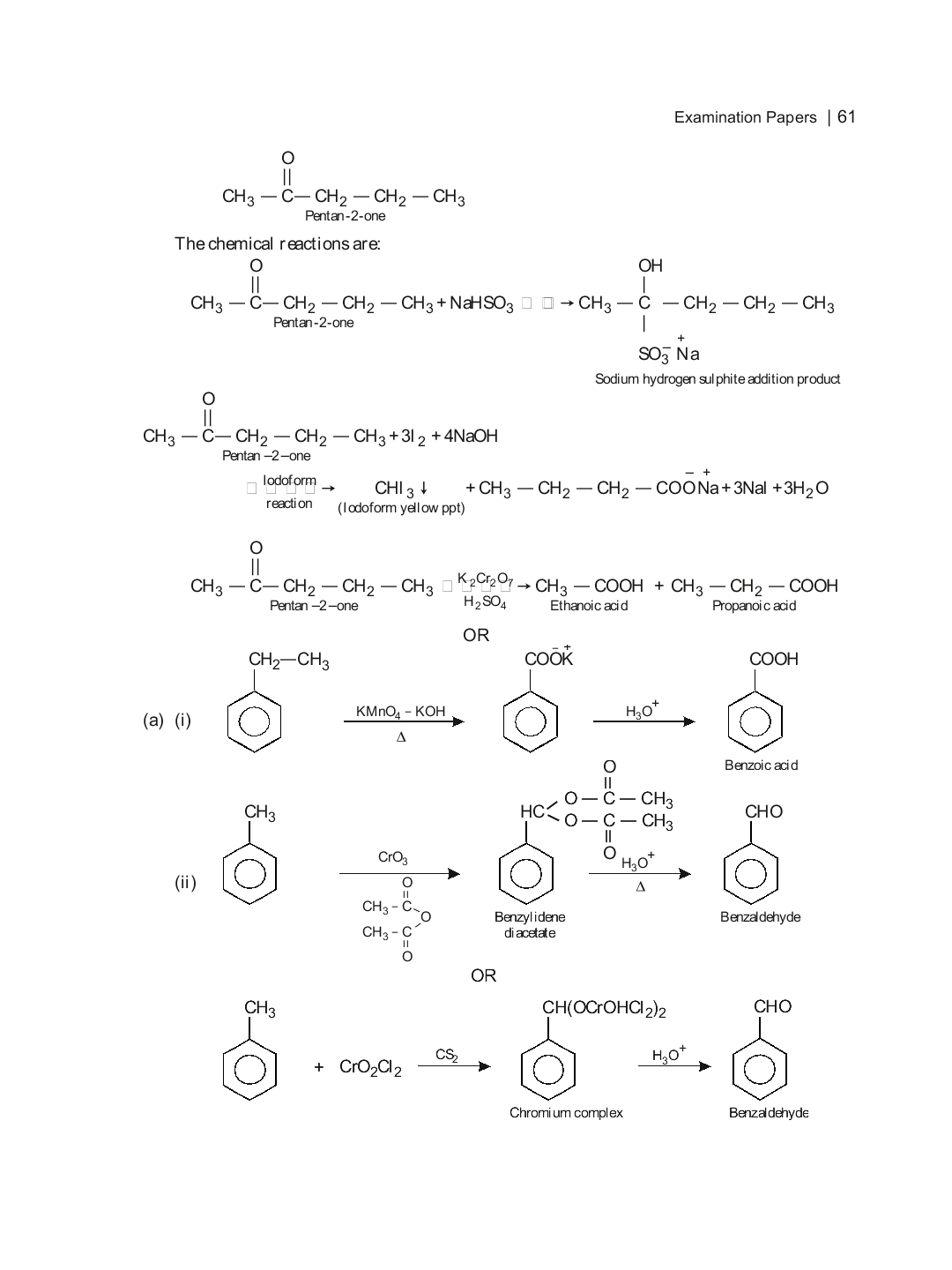
在这里,只有一些箭头更薄,而一些箭头部分被错误地绘制成盒子.
因此,
如何使pdfbox获取类似于直接快照图像的内容?
当前的版本(高达1.8.4)在将PDF呈现为图像时似乎有更大的缺陷。您可以切换到当前的开发版本(例如,当前主干,2.0.0-快照),或者等到改进发布。
此外,一些轻微的赤字甚至出现在2.0.0的快照中。您可能希望将您的示例文档提交给PDFBox人员(即在他们的JIRA中创建一个相应的问题),以便他们进一步改进PDFBox以满足您的需要。
另外,我注意到png的图像质量不太好,有没有办法提高产生的图像的分辨率?
存在带有convertToImage参数的resolution重载。您的当前代码实际上将解析设置为screenResolution。增加此分辨率值。
PS:将PDF页面呈现到图像的代码已在2.0.0-快照中重构。而不是
BufferedImage image = page.convertToImage();你现在做了
BufferedImage image = RenderUtil.convertToImage(page);我假设这样做是为了从核心类中删除直接的AWT引用,因为AWT在例如Android上是不可用的。
PS:我去年在这个答案中使用的快照只是一个受更改的快照。这个2.0.0版本还在开发中,很多事情已经改变了。特别是再也没有RenderUtil类了。相反,目前必须在PDFRenderer包中使用org.apache.pdfbox.rendering .
https://stackoverflow.com/questions/22332791
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号