
逆概率密度函数
逆概率密度函数
提问于 2014-03-08 02:01:55
用什么方法计算正态分布的概率密度函数?我用正态概率密度函数来求出:
from scipy.stats import norm
norm.pdf(1000, loc=1040, scale=210)
0.0018655737107410499在给定的正态分布中,我如何计算出0.0018的概率对应于1000?
回答 2
Stack Overflow用户
回答已采纳
发布于 2014-03-08 02:15:07
从概率密度到分位数不可能有1:1映射。
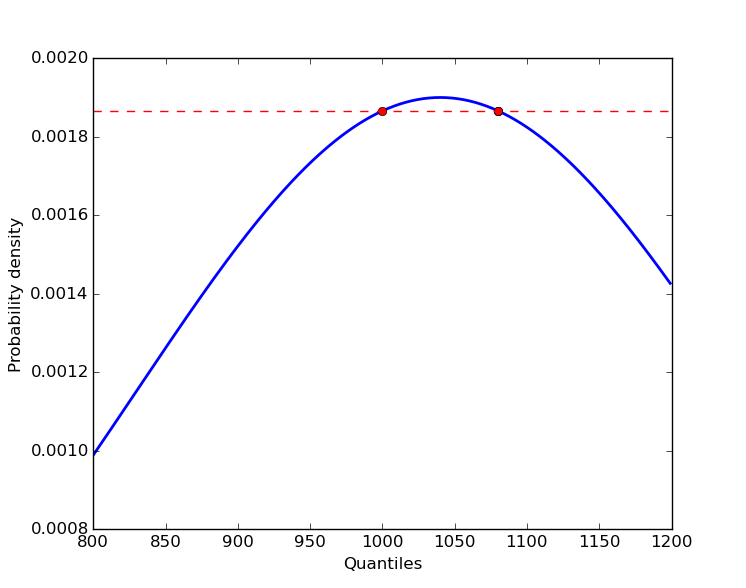
由于正态分布的PDF是二次型的,所以可以有2,1或零分位数,它们具有特定的概率密度。
更新
实际上,要从分析中找到根源并不难。正态分布的PDF由:
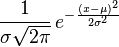
经过一些重新安排,我们得到:
(x - mu)**2 = -2 * sigma**2 * log( pd * sigma * sqrt(2 * pi))如果RHS上的判别式< 0,则没有真正的根。如果它等于零,就有一个根(其中x= mu),当它>0时有两个根。
把它放在一起变成一个函数:
import numpy as np
def get_quantiles(pd, mu, sigma):
discrim = -2 * sigma**2 * np.log(pd * sigma * np.sqrt(2 * np.pi))
# no real roots
if discrim < 0:
return None
# one root, where x == mu
elif discrim == 0:
return mu
# two roots
else:
return mu - np.sqrt(discrim), mu + np.sqrt(discrim)这使所需的分位数在四舍五入误差范围内:
from scipy.stats import norm
pd = norm.pdf(1000, loc=1040, scale=210)
print get_quantiles(pd, 1040, 210)
# (1000.0000000000001, 1079.9999999999998)Stack Overflow用户
发布于 2014-03-08 02:47:02
import scipy.stats as stats
import scipy.optimize as optimize
norm = stats.norm(loc=1040, scale=210)
y = norm.pdf(1000)
print(y)
# 0.00186557371074
print(optimize.fsolve(lambda x:norm.pdf(x)-y, norm.mean()-norm.std()))
# [ 1000.]
print(optimize.fsolve(lambda x:norm.pdf(x)-y, norm.mean()+norm.std()))
# [ 1080.]存在着达到任意值无限次的分布。(例如,在长度为1/2、1/4、1/8等的无限间隔序列上,值为1的简单函数获得无穷次的值。它是一个分布,因为1/2 + 1/4 + 1/8 +…= 1)
因此,以上fsolve的使用并不能保证找到x的所有值,其中pdf(x)等于某个值,但它可能会帮助您找到一些根。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/22264046
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号