
直方图中的峰值数
我有代表某些强度值的一维数据。我希望检测这些数据中的组件数量(具有相似强度的点簇,或者从这些数据创建的直方图中的“峰值”的数量)。
这种方法:一维多峰检测?对我不是很有用,因为一个“峰值”可以包含更多的局部最大值(见下图)。
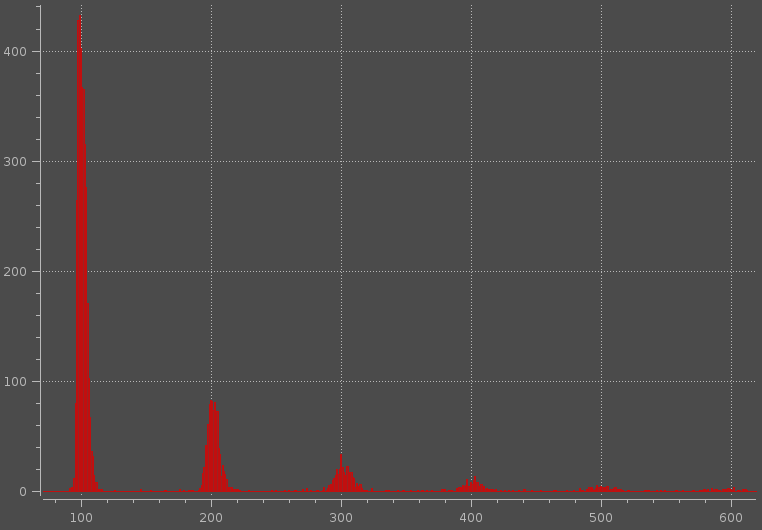
当然,我可以使用统计方法,例如,我可以尝试对1,2,3,....n峰值的数据进行拟合,然后计算比克、AIC或任何其他匹配值。最后利用弯头法进行聚类数的确定。然而,我希望尽可能快地检测出大约的峰值数,并且拟合高斯混合是相当耗时的过程。
My approach
因此,我提出了以下方法(在C++中)。它取直方图箱高度(y),并搜索y值开始下降的指数。然后对小于y公差(yt)的值进行滤波。最后,使用x公差(xt)的索引也会被过滤:
Indices StatUtils::findLocalMaximas(const Points1D &y, int xt, int yt) {
// Result indices
Indices indices;
// Find all local maximas
int imax = 0;
double max = y[0];
bool inc = true;
bool dec = false;
for (int i = 1; i < y.size(); i++) {
// Changed from decline to increase, reset maximum
if (dec && y[i - 1] < y[i]) {
max = std::numeric_limits<double>::min();
dec = false;
inc = true;
}
// Changed from increase to decline, save index of maximum
if (inc && y[i - 1] > y[i]) {
indices.append(imax);
dec = true;
inc = false;
}
// Update maximum
if (y[i] > max) {
max = y[i];
imax = i;
}
}
// If peak size is too small, ignore it
int i = 0;
while (indices.count() >= 1 && i < indices.count()) {
if (y[indices.at(i)] < yt) {
indices.removeAt(i);
} else {
i++;
}
}
// If two peaks are near to each other, take only the largest one
i = 1;
while (indices.count() >= 2 && i < indices.count()) {
int index1 = indices.at(i - 1);
int index2 = indices.at(i);
if (abs(index1 - index2) < xt) {
indices.removeAt(y[index1] < y[index2] ? i-1 : i);
} else {
i++;
}
}
return indices;
}问题与逼近
这个解决方案的问题在于,在很大程度上取决于这些容差值(xt和yt)。所以我必须要有关于山峰之间最小允许距离的信息。此外,在我的数据中有一些孤立的离群点,它们比这些较小的峰值的最大值要高。
您能否建议其他一些方法,如何确定类似于附图中的数据的峰值数。
回答 1
Stack Overflow用户
发布于 2014-03-04 11:08:18
你可以用我的近似高斯混合方法
- 这是一种稳健的统计方法。
- 它不依赖于绝对阈值;它只有两个参数,它们是相对(规范化)数量,易于控制,相同的值适用于不同的数据集。
- 与弯头法和大多数统计方法不同的是,它动态地估计单个EM (预期-最大化)运行中的模态数。它以每个数据点作为独立模式开始,并在每次迭代中删除“重叠”模式。
- 它是快速的,因为它在每次迭代中都使用了近似最近邻(ANN)搜索,并且它的更新只考虑了k个最近的邻居,而不是所有的数据点。
有一个在线的Matlab演示,所以您可以轻松地在一个小的数据集上进行实验。在我们的C++实现中,我们大规模地使用弗兰进行最近邻搜索。不幸的是,这个实现不是公开的,但是如果您感兴趣的话,我可以给您提供一些版本。
https://stackoverflow.com/questions/22169492
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号