
默认流中始终启动CUBLAS gemm中的memset
我注意到,当从主机调用每个gemm的cublasSgemm函数时,有三个内核调用: memset、scal_kernel和gemm内核本身(例如sgemm_large)。即使我使用在设备内存中分配的常量alpha/beta,也会发生这种情况。虽然memset和scal_kernel的开销相对较小,但问题是memset总是在默认流中启动,这会导致不必要的同步。
守则:
__constant__ __device__ float alpha = 1;
__constant__ __device__ float beta = 1;
int main()
{
// ... memory allocation skipped ...
float* px = thrust::raw_pointer_cast(x.data());
float* py = thrust::raw_pointer_cast(y.data());
float* pmat = thrust::raw_pointer_cast(mat.data());
for (int iter = 0; iter < 3; ++iter)
{
cbstatus = cublasSgemm(cbh, CUBLAS_OP_N, CUBLAS_OP_N, crow, ccol, cshared, &alpha, px, crow, py, cshared, &beta, pmat, crow);
assert(0 == cbstatus);
}
}这就是我在分析器中看到的:
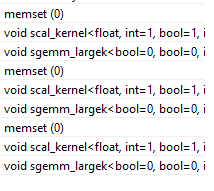
问题:是否有一种方法可以避免memset或使它在分配给CUBLAS句柄的流中运行?一个想法是使用DP和运行gemm功能的设备版本,但这将只在CC3.0和更高版本上工作。
回答 2
Stack Overflow用户
发布于 2014-02-26 22:20:47
在CUBLAS5.5中有一个bug,在专门路径中使用cudaMemset而不是cudaMemsetAsync,其中k >> m,n。
它是固定在CUBLAS6.0RC。如果你是一个注册开发人员,你可以访问它。
顺便说一句,我不知道为什么你用__constant__ __device__作为alpha,beta。你在用pointerMode = DEVICE吗
如果没有,您可以简单地在主机上使用alpha,beta。
Stack Overflow用户
发布于 2014-02-26 22:10:09
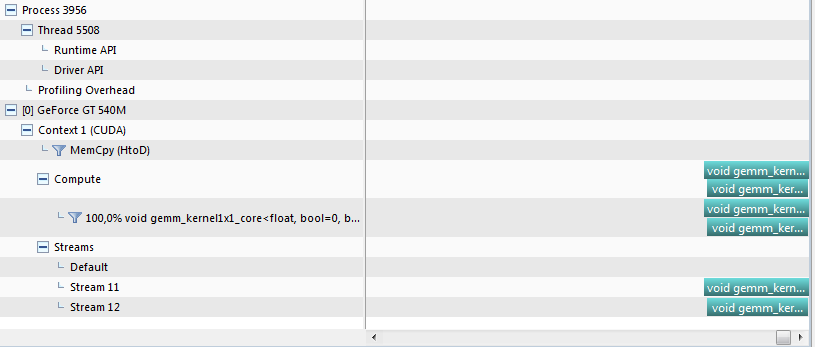
试试下面的代码。除了不可避免的内存分配和拷贝之外,代码只包含一个cublasSgemm调用。你会看到的
- 您只有一个内核启动(
gemm_kernel1x1_core); - 对
cublasSgemm的两个调用在两个不同的流中完美地运行。
在图片中,将显示时间线。
我的系统: GeForce 540 M,Windows 7,CUDA 5.5。
#include <conio.h>
#include <stdio.h>
#include <assert.h>
#include <cublas_v2.h>
/********************/
/* CUDA ERROR CHECK */
/********************/
#define gpuErrchk(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, char *file, int line, bool abort=true)
{
if (code != cudaSuccess)
{
fprintf(stderr,"GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) { getchar(); exit(code); }
}
}
/**********************/
/* cuBLAS ERROR CHECK */
/**********************/
#ifndef cublasSafeCall
#define cublasSafeCall(err) __cublasSafeCall(err, __FILE__, __LINE__)
#endif
inline void __cublasSafeCall(cublasStatus_t err, const char *file, const int line)
{
if( CUBLAS_STATUS_SUCCESS != err) {
fprintf(stderr, "CUBLAS error in file '%s', line %d\n \nerror %d \nterminating!\n",__FILE__, __LINE__,err);
getch(); cudaDeviceReset(); assert(0);
}
}
/********/
/* MAIN */
/********/
int main()
{
int N = 5;
float *A1, *A2, *B1, *B2, *C1, *C2;
float *d_A1, *d_A2, *d_B1, *d_B2, *d_C1, *d_C2;
A1 = (float*)malloc(N*N*sizeof(float));
B1 = (float*)malloc(N*N*sizeof(float));
C1 = (float*)malloc(N*N*sizeof(float));
A2 = (float*)malloc(N*N*sizeof(float));
B2 = (float*)malloc(N*N*sizeof(float));
C2 = (float*)malloc(N*N*sizeof(float));
gpuErrchk(cudaMalloc((void**)&d_A1,N*N*sizeof(float)));
gpuErrchk(cudaMalloc((void**)&d_B1,N*N*sizeof(float)));
gpuErrchk(cudaMalloc((void**)&d_C1,N*N*sizeof(float)));
gpuErrchk(cudaMalloc((void**)&d_A2,N*N*sizeof(float)));
gpuErrchk(cudaMalloc((void**)&d_B2,N*N*sizeof(float)));
gpuErrchk(cudaMalloc((void**)&d_C2,N*N*sizeof(float)));
for (int i=0; i<N*N; i++) {
A1[i] = ((float)rand()/(float)RAND_MAX);
A2[i] = ((float)rand()/(float)RAND_MAX);
B1[i] = ((float)rand()/(float)RAND_MAX);
B2[i] = ((float)rand()/(float)RAND_MAX);
}
gpuErrchk(cudaMemcpy(d_A1, A1, N*N*sizeof(float), cudaMemcpyHostToDevice));
gpuErrchk(cudaMemcpy(d_B1, B1, N*N*sizeof(float), cudaMemcpyHostToDevice));
gpuErrchk(cudaMemcpy(d_A2, A2, N*N*sizeof(float), cudaMemcpyHostToDevice));
gpuErrchk(cudaMemcpy(d_B2, B2, N*N*sizeof(float), cudaMemcpyHostToDevice));
cublasHandle_t handle;
cublasSafeCall(cublasCreate(&handle));
cudaStream_t stream1, stream2;
gpuErrchk(cudaStreamCreate(&stream1));
gpuErrchk(cudaStreamCreate(&stream2));
float alpha = 1.f;
float beta = 1.f;
cublasSafeCall(cublasSetStream(handle,stream1));
cublasSafeCall(cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A1, N, d_B1, N, &beta, d_C1, N));
cublasSafeCall(cublasSetStream(handle,stream2));
cublasSafeCall(cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A2, N, d_B2, N, &beta, d_C2, N));
gpuErrchk(cudaDeviceReset());
return 0;
}https://stackoverflow.com/questions/22049497
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号