
数据库优化设计
几年前,我为在PHP、JavaScript和MySQL学习的11-16名学生设计了一个奖励系统。
前提很简单:
- 教职员工问题指的是不同类别的学生(“积极的态度和行为”、“模范公民”等)。
- 学生将这些积分加在我们的网上商店(iTunes代金券等)。
现有制度
数据库结构也很简单(可能太多了):
交易记录
239 189行
CREATE TABLE `transactions` (
`Transaction_ID` int(9) NOT NULL auto_increment,
`Datetime` date NOT NULL,
`Giver_ID` int(9) NOT NULL,
`Recipient_ID` int(9) NOT NULL,
`Points` int(4) NOT NULL,
`Category_ID` int(3) NOT NULL,
`Reason` text NOT NULL,
PRIMARY KEY (`Transaction_ID`),
KEY `Giver_ID` (`Giver_ID`),
KEY `Datetime` (`Datetime`),
KEY `DatetimeAndGiverID` (`Datetime`,`Giver_ID`),
KEY `Recipient_ID` (`Recipient_ID`)
) ENGINE=InnoDB AUTO_INCREMENT=249069 DEFAULT CHARSET=latin1类别
34行
CREATE TABLE `categories` (
`Category_ID` int(9) NOT NULL,
`Title` varchar(255) NOT NULL,
`Description` text NOT NULL,
`Default_Points` int(3) NOT NULL,
`Groups` varchar(125) NOT NULL,
`Display_Start` datetime default NULL,
`Display_End` datetime default NULL,
PRIMARY KEY (`Category_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1奖励
82行
CREATE TABLE `rewards` (
`Reward_ID` int(9) NOT NULL auto_increment,
`Title` varchar(255) NOT NULL,
`Description` text NOT NULL,
`Image_URL` varchar(255) NOT NULL,
`Date_Inactive` datetime NOT NULL,
`Stock_Count` int(3) NOT NULL,
`Cost_to_User` float NOT NULL,
`Cost_to_System` float NOT NULL,
PRIMARY KEY (`Reward_ID`)
) ENGINE=InnoDB AUTO_INCREMENT=91 DEFAULT CHARSET=latin1购买
5,889行
CREATE TABLE `purchases` (
`Purchase_ID` int(9) NOT NULL auto_increment,
`Datetime` datetime NOT NULL,
`Reward_ID` int(9) NOT NULL,
`Quantity` int(4) NOT NULL,
`Student_ID` int(9) NOT NULL,
`Student_Name` varchar(255) NOT NULL,
`Date_DealtWith` datetime default NULL,
`Date_Collected` datetime default NULL,
PRIMARY KEY (`Purchase_ID`)
) ENGINE=InnoDB AUTO_INCREMENT=6133 DEFAULT CHARSET=latin1问题
这个系统在一段时间内运行得很好。现在,在某些查询中,它开始大幅度放慢速度。
本质上,每次我需要访问一个学生的奖励积分总数,所需的查询需要很长时间。下面是几个示例查询及其运行时间:
全校前15名学生(不包括出勤率类别)
SELECT CONCAT( s.Firstname, " ", s.Surname ) AS `Student` , s.Year_Group AS `Year Group`, SUM( t.Points ) AS `Points`
FROM frog_rewards.transactions t
LEFT JOIN frog_shared.student s ON t.Recipient_ID = s.id
WHERE t.Datetime > '2013-09-01' AND t.Category_ID NOT IN ( 12, 13, 14, 26 )
GROUP BY t.Recipient_ID
ORDER BY `Points` DESC
LIMIT 0 , 15

- 运行时间:44.8425秒
SELECT Recipient_ID, SUM(points) AS Total_Points FROM事务GROUP BY Recipient_ID

- 运行时间:9.8698秒
现在我意识到,尤其是在第二个查询中,我不应该运行一个会返回这么多行的调用,但是系统运行的框架的局限性意味着,如果我想显示学生对教师/导师/年度经理/领导力的总奖励积分,我就没有其他选择了。
解决方案的时间
幸运的是,我们被迫使用的框架正在改变。我们现在将使用oAuth,而不是一种可怕的过时的JavaScript小部件格式。
不幸的是,我想,幸运的是,这意味着我们将不得不重写相当多的系统。
在重写系统时,我打算考虑的主要领域之一是数据库结构。随着时间的推移,它只会变得更大,所以我需要做一些未来的打样。
因此,我的主要问题是:,什么是存储学生点数总和的最有效的方法?
我唯一能想到的想法是有一个单独的表,名为totals,其中包含Student_ID和Points字段。每次工作人员发布一些要点时,它都会将一行添加到transactions表中,但也会更新totals表。
这有效率吗?是否也有一个Points_Since_Monday类型字段是有效的?我将如何更新/保持在此之上?
除了主要问题外,如果有人对数据库表的优化提出建议,请告诉我。
谢谢你,邓肯
回答 1
Stack Overflow用户
发布于 2014-02-06 21:04:52
没有什么特别的错误,你的设计,这应该使它像你报告的那样慢。我认为肯定还有其他因素在起作用,例如,它在重载或慢运行时运行的服务器。只有你才能知道是否是这样。
为了测试您的设计,我在我的桌面计算机上运行的2008年Server上重新创建了它。我有一个标准的电脑,单硬盘,没有SSD,没有raid等,所以在一个合适的数据库服务器上的结果应该会更好。当您使用MySQL时,我不得不对设计进行一些更改,但是所有的更改都不应该影响性能,这只是为了在我的数据库上运行它。
下面是我使用的表结构,我不得不猜测在Student和Staff表中会有哪些内容,因为您并不需要这些表。我还冒昧地为Giver_ID和Receiver_ID更改了Giver_ID和Receiver_ID表中的字段名,因为我假设只有工作人员才能给出分数,而学生才能得到它们。
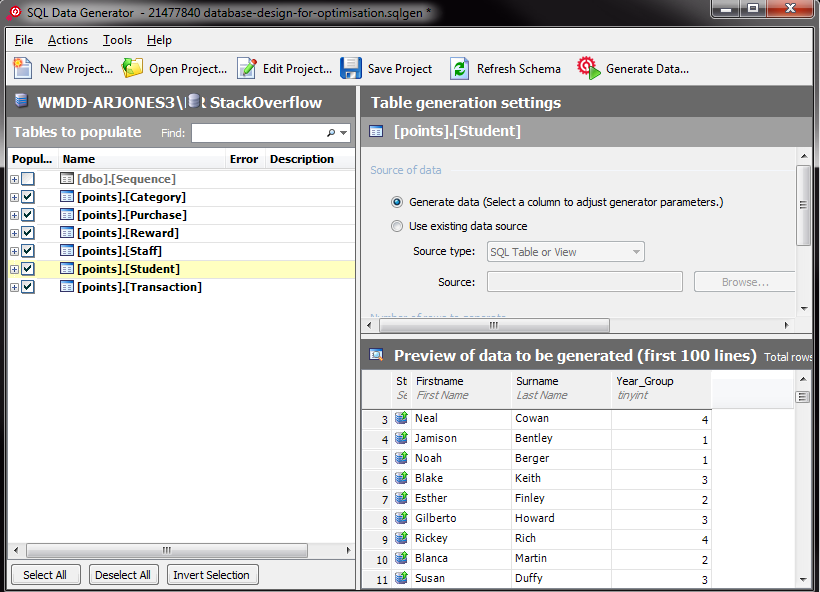
我生成随机数据来填充表中的行数与您说的数据库中的行数相同。
我运行了你说需要很长时间的两个查询,我已经修改了它们以适应我的设计,但我(希望)结果是一样的
SELECT TOP 15
Firstname + ' ' + Surname
,Year_Group
,SUM(Points) AS Points
FROM points.[Transaction]
INNER JOIN points.Student ON points.[Transaction].Student_ID = points.Student.Student_ID
WHERE [Datetime] > '2013-09-01'
AND Category_ID NOT IN ( 12, 13, 14, 26 )
GROUP BY Firstname + ' ' + Surname
,Year_Group
ORDER BY SUM(Points) DESC
SELECT Student_ID
,SUM(Points) AS Total_Points
FROM points.[Transaction]
GROUP BY Student_ID两个查询都返回大约1s的结果。除了在主键上默认生成的CLUSTERED索引之外,我没有在表上创建任何其他索引。从执行计划来看,查询处理器估计,实现以下索引可以使查询成本提高81.0309%
CREATE NONCLUSTERED INDEX [<Name of Missing Index>]
ON [points].[Transaction] ([Datetime],[Category_ID])
INCLUDE ([Student_ID],[Points])
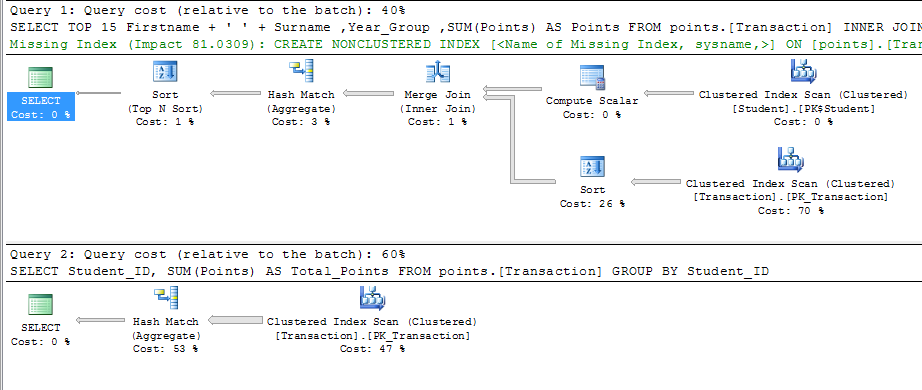
正如其他人所评论的,在花费大量时间重新设计数据库之前,我会在其他地方寻找瓶颈。
更新:
我意识到我从来没有真正回答过你的具体问题:
储存学生积分的最有效的方法是什么? 我唯一能想到的想法是有一个单独的表,名为Student_ID和Point字段的总计。每次工作人员发布某些点数时,它都会将一行添加到transactions表中,但也会更新updates表。
我不建议保留一个单独的点总数,除非您已经探索了加速数据库的所有其他可能的方法。一个单独的统计可能会与事务不同步,然后您必须协调所有事情,并跟踪错误的地方,以及正确的总数应该是什么。
在试图提高速度之前,您应该始终关注于维护数据的正确性和一致性。大多数情况下,一个正确(标准化)的数据模型将运行得足够快。
在我工作的一个地方,我们发现加快数据库速度的最具成本效益的方法就是简单地升级硬件;比花费大量人工时间重新设计数据库要快得多,也便宜得多:)
https://stackoverflow.com/questions/21477840
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号