
R-创建一个反方频率矩阵。
我有易货经济的数据。我正试图创建一个矩阵,以计算项目作为对手方与其他项目之间的频繁程度。
例如:
myDat <- data.frame(
TradeID = as.factor(c(1,1,1,2,2,2,3,3,4,4,5,5,6,6,7,7,8,8,8)),
Origin = as.factor(c(1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,1,0,0)),
ItemID = as.factor(c(1,2,3,4,5,1,1,6,7,1,1,8,7,5,1,1,2,3,4))
)
TradeID Origin ItemID
1 1 1 1
2 1 0 2
3 1 0 3
4 2 1 4
5 2 1 5
6 2 0 1
7 3 1 1
8 3 0 6
9 4 1 7
10 4 0 1
11 5 1 1
12 5 0 8
13 6 1 7
14 6 0 5
15 7 1 1
16 7 0 1
17 8 1 2
18 8 0 3
19 8 0 4
20 9 1 1
21 9 0 8其中TradeID表示特定的事务。ItemID表示一项,而原产地表示该项的去向。
例如,考虑到我的数据,我要创建的矩阵如下所示:
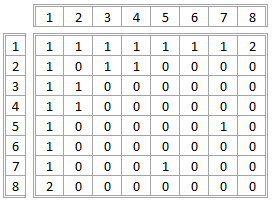
- 例如,1,8的价值2表示第1和第8项是两个交易的对手方。(注意,它是一个对称矩阵,所以8,1也有值2)。
- 1 at 1,2表示第1项和第2项仅是一项交易的对手方(整个矩阵中的所有其他1s表示相同)。
- 作为一个奇怪的例子,注1,1的值表示项目1曾经是自己的交易对手(交易号7)。
- 多了解一下我的动机,注意在我的简单例子中,第1项倾向于在许多不同的项目中充当对手方。在易货经济(一个没有明确货币的经济体)中,我们可能会期望一种商品货币比非商品货币更频繁地成为交易对手。这样的矩阵将是发现哪一个项目是商品货币的第一步。
我已经为这事挣扎了一段时间了。但是我想我已经差不多完成了一个过于复杂的解决方案,我很快就会发布。
我很好奇你们是否也能提供点帮助。
回答 3
Stack Overflow用户
发布于 2014-01-28 21:05:47
好吧,我想我已经弄清楚了。简单的答案是:
Reduce("+",by(myDat, myDat$TradeID, function(x) pmin(table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]) + table(x$ItemID[x$Origin==1]) %o% table(x$ItemID[x$Origin==0]),1)))它提供了以下矩阵,匹配所需的结果:
1 2 3 4 5 6 7 8
1 1 1 1 1 1 1 1 2
2 1 0 1 1 0 0 0 0
3 1 1 0 0 0 0 0 0
4 1 1 0 0 0 0 0 0
5 1 0 0 0 0 0 1 0
6 1 0 0 0 0 0 0 0
7 1 0 0 0 1 0 0 0
8 2 0 0 0 0 0 0 0长话短说。您可以使用by和outer (%o%)和table函数来获取每个outer的矩阵列表。但是这个双计数贸易7,其中项目1是交易项目1,所以我使用pmax函数来修复这个问题。然后,我使用Reduce函数对整个列表进行求和。
这是到达那里的步骤。注意添加了TradeID # 9,它被排除在问题的代码之外。
# Data
myDat <- data.frame(
TradeID = as.factor(c(1,1,1,2,2,2,3,3,4,4,5,5,6,6,7,7,8,8,8,9,9)),
Origin = as.factor(c(1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,1,0,0,1,0)),
ItemID = as.factor(c(1,2,3,4,5,1,1,6,7,1,1,8,7,5,1,1,2,3,4,1,8))
)
# Sum in 1 direction
by(myDat, myDat$TradeID, function(x) table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]))
# Sum in both directions
by(myDat, myDat$TradeID, function(x) table(x$ItemID[x$Origin==1]) %o% table(x$ItemID[x$Origin==0]) + table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]))
# Remove double-count in trade 7
by(myDat, myDat$TradeID, function(x) pmin(table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]) + table(x$ItemID[x$Origin==1]) %o% table(x$ItemID[x$Origin==0]),1))
# Sum across lists
Reduce("+",by(myDat, myDat$TradeID, function(x) pmin(table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]) + table(x$ItemID[x$Origin==1]) %o% table(x$ItemID[x$Origin==0]),1)))加快这一速度的一种方法是只向一个方向求和(利用对称性),然后清理结果。
result = Reduce("+",by(myDat, myDat$TradeID, function(x) table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1])))
result2 = result + t(result)
diag(result2) = diag(result)
result2
1 2 3 4 5 6 7 8
1 1 1 1 1 1 1 1 2
2 1 0 1 1 0 0 0 0
3 1 1 0 0 0 0 0 0
4 1 1 0 0 0 0 0 0
5 1 0 0 0 0 0 1 0
6 1 0 0 0 0 0 0 0
7 1 0 0 0 1 0 0 0
8 2 0 0 0 0 0 0 0这个速度似乎是原来的两倍。
> microbenchmark(Reduce("+",by(myDat, myDat$TradeID, function(x) pmin(table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]) + table(x$ItemID[x$Origin==1]) %o% table(x$ItemID[x$Origin==0]),1))))
Unit: milliseconds
min lq median uq max neval
7.489092 7.733382 7.955861 8.536359 9.83216 100
> microbenchmark(Reduce("+",by(myDat, myDat$TradeID, function(x) table(x$ItemID[x$Origin==0]) %o% table(x$ItemID[x$Origin==1]))))
Unit: milliseconds
min lq median uq max neval
4.023964 4.18819 4.277767 4.452824 5.801171 100Stack Overflow用户
发布于 2014-01-28 20:00:03
这将给出每个TradeID和ItemID的观测数。
myDat <- data.frame(
TradeID = as.factor(c(1,1,1,2,2,2,3,3,4,4,5,5,6,6,7,7,8,8,8)),
Origin = as.factor(c(1,0,0,1,1,0,1,0,1,0,1,0,1,0,1,0,1,0,0)),
ItemID = as.factor(c(1,2,3,4,5,1,1,6,7,1,1,8,7,5,1,1,2,3,4))
)
result = tapply(myDat$Origin, list(myDat$ItemID,myDat$TradeID), length)
result[is.na(result)] = 0
result["1","7"]结果将是:
> result
1 2 3 4 5 6 7 8
1 1 1 1 1 1 0 2 0
2 1 0 0 0 0 0 0 1
3 1 0 0 0 0 0 0 1
4 0 1 0 0 0 0 0 1
5 0 1 0 0 0 1 0 0
6 0 0 1 0 0 0 0 0
7 0 0 0 1 0 1 0 0
8 0 0 0 0 1 0 0 0这将给出1 Origin与TradeID和ItemID的比例。
result = tapply(myDat$Origin, list(myDat$ItemID,myDat$TradeID), function(x) { sum(as.numeric(as.character(x)))/length(x) })您可以使用NA将最后一个矩阵中的result[is.na(result)] = 0值设置为0,但这将不会将任何观察与0原产地交易混淆。
Stack Overflow用户
发布于 2014-01-28 20:25:18
这将给出每一个连续的ItemIDs的观察数:
idxList <- with(myDat, tapply(ItemID, TradeID, FUN = function(items)
lapply(seq(length(items) - 1),
function(i) sort(c(items[i], items[i + 1])))))
# indices of observations
idx <- do.call(rbind, unlist(idxList, recursive = FALSE))
# create a matrix
ids <- unique(myDat$ItemID)
mat <- matrix(0, length(ids), length(ids))
# place values in matrix
for (i in seq(nrow(idx))) {
mat[idx[i, , drop = FALSE]] <- mat[idx[i, , drop = FALSE]] + 1
}
# create symmatric marix
mat[lower.tri(mat)] <- t(mat)[lower.tri(mat)]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 1 1 0 0 1 1 1 1
[2,] 1 0 2 0 0 0 0 0
[3,] 0 2 0 1 0 0 0 0
[4,] 0 0 1 0 1 0 0 0
[5,] 1 0 0 1 0 0 1 0
[6,] 1 0 0 0 0 0 0 0
[7,] 1 0 0 0 1 0 0 0
[8,] 1 0 0 0 0 0 0 0https://stackoverflow.com/questions/21415159
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号