
LSA -特征选择
我有这份文件的SVD分解
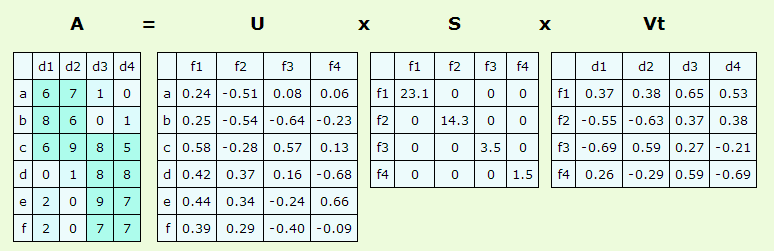
我读过此页,但我不明白如何计算文档分离的最佳特性。
我知道:
S x Vt给出了文档和特性之间的关系
U x S给出了术语和特征之间的关系
但是,最佳特征选择的关键是什么?
回答 1
Stack Overflow用户
发布于 2014-01-28 11:47:40
SVD只关注输入,而不关心它们的标签。换句话说,它可以被看作是一种无监督的技术。因此,它不能告诉您哪些特性有利于分离,而不作任何进一步的假设。
它告诉你的是,什么‘基向量’比其他更重要,在重建原始数据时,只使用基向量的子集。
然而,您可以通过以下方式来考虑LSA (这只是解释,数学才是最重要的):文档是由多种主题生成的。每个主题都由长度为n的向量表示,它告诉您这个主题中每个单词的可能性。例如,如果主题是sports,那么像football或game这样的词比bestseller或movie更有可能出现。这些主题向量是U的列,为了生成一个文档(a的一个列),您采用了主题的线性组合。线性组合的系数是Vt的列-每一列都告诉您要生成文档的主题比例。此外,每个主题都有一个总体的“增益”因子,它告诉您这个主题在您的文档集中有多重要(可能在1000个文档中只有一个关于体育的文档)。这些是奇异值==,S的对角线,如果你扔掉较小的矩阵,你可以用较少的主题和少量的信息来表示你原来的矩阵A。当然,“小”是一个应用问题。
LSA的一个缺点是不完全清楚如何解释这些数字--例如,它们不是概率。在文档中使用"0.5“单位sports是有意义的,但是拥有"-1”单位意味着什么呢?
https://stackoverflow.com/questions/21401926
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号