
Antlrworks -外来输入
Antlrworks -外来输入
提问于 2014-01-20 19:42:42
我是新来的,因此我需要你的帮助。我正试图解析Wikipedia转储,我的第一步是将它们定义的每条规则映射到ANTLR,不幸的是,我遇到了第一个障碍:
第1行:8外来输入“”期待“\”
我不明白发生了什么事,请你帮我一下。
我的代码:
grammar Test;
options {
language = Java;
}
parse
: term+ EOF
;
term
: IDENT
| '[[' term ']]'
| '\'\'' term '\'\''
| '\'\'\'' term '\'\'\''
;
IDENT
: ('a'..'z' | 'A'..'Z' | '0'..'9' | '=' | '#' | '"' | ' ')*
;
输入‘Hello’
回答 1
Stack Overflow用户
发布于 2014-01-20 20:02:13
词汇规则必须始终与至少一个字符匹配。你的规则:
IDENT : ('a'..'z' | 'A'..'Z' | '0'..'9' | '=' | '#' | '"' | ' ')*;匹配一个空字符串(其中有无限数量的)。将*更改为+
IDENT : ('a'..'z' | 'A'..'Z' | '0'..'9' | '=' | '#' | '"' | ' ')+;编辑
输入
'''''Hello World'''''
尽管您在解析器规则('\'\'\''、'\'\''等)中放置了文字标记,但您必须明白,它们不是按照解析器的要求创建的。lexer遵循严格的规则来创建令牌:
- 它试图尽可能地匹配
- 如果两个不同的词法规则匹配相同数量的字符,那么第一个先定义的规则将获得优先权。
让我们给您的文字标记取一个名称:
BRACKET_OPEN : '[[';
BRACKET_CLOSE : ']]';
Q3 : '\'\'\'';
Q2 : '\'\'';
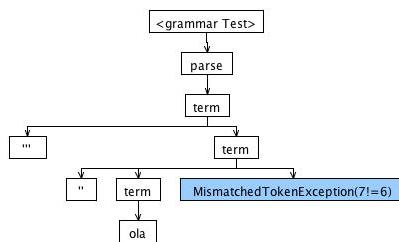
IDENT : ('a'..'z' | 'A'..'Z' | '0'..'9' | '=' | '#' | '"' | ' ')+;现在,由于规则#1 (尽可能匹配),输入'''''Hello World'''''将被标记如下:
Q3Q2IDENTQ3(是的,Q3!)Q2
但是解析器规则term只接受Q3 Q2 IDENT Q2 Q3,因此输入不能正确解析是正确的。
另外,我建议您不要使用解释器:这是相当多的错误。调试器的工作就像一个魅力!
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/21242730
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号