
网络中的节点关系?
我有两栏A和B,分别包含不同组织和不同基金的I。A栏有1 200个不同的值(不同的组织),并有重复。B栏有大约350个不同的数值(不同的资金)和重复。每一行约有8 500行,每一行不同,因为它们代表从一个基金向一个组织提供的赠款。
问题是,多个基金向同一个组织提供赠款,因此这些基金基本上是通过赠款相互“联系”的。
我想找出,1)基金的数量与其他基金有关,2)基金之间的联系最紧密。
这有道理吗?如果是这样的话,你如何解决这些价值?我在Server中提取数据,并尝试使用R包、NodeXL和一些嵌套的Excel函数,但都没有效果。我失去了我的能力。
回答 1
Stack Overflow用户
发布于 2014-01-15 18:59:07
如果我正确理解你的问题,这就是你所需要的。
select b.fund, COUNT(*)
from yourtable a inner join yourtable b on a.org = b.org
group by b.fund order by COUNT(*) desc这将返回与其相关联的基金的身份(注:它将对事物进行两次计数,例如,如果(org1,fund1)和(org2,fund1)和(org1,fund2)存在,则返回( fund1,3),( fund2,3),因为与与fund1和fund2相关联的组织有三种基金关系。
如果您只想计算参与此关系的不同基金,请使用:
select b.fund, COUNT(distinct a.fund)
from yourtable a inner join yourtable b on a.org = b.org
group by b.fund order by COUNT(distinct a.fund) desc请注意,这将自己计算在内。
这两家公司都会自动订购数量最多的相关基金。
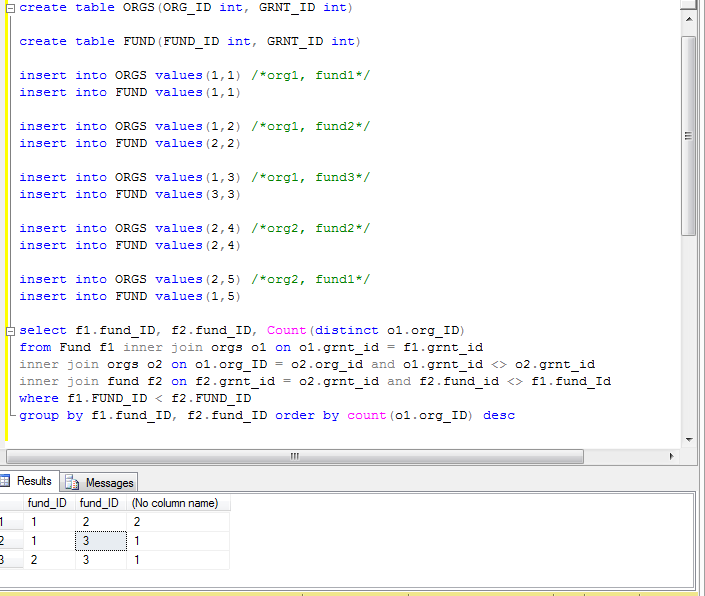
编辑:在了解有关问题和表结构的更多信息后,我认为这是可行的:
select f1.fund_ID, f2.fund_ID, Count(distinct o1.org_ID)
from Fund f1 inner join orgs o1 on o1.grnt_id = f1.grnt_id
inner join orgs o2 on o1.org_ID = o2.org_id and o1.grnt_id <> o2.grnt_id
inner join fund f2 on f2.grnt_id = o2.grnt_id and f2.fund_id <> f1.fund_Id
where f1.FUND_ID < f2.FUND_ID
group by f1.fund_ID, f2.fund_ID order by count(o1.org_ID) desc
https://stackoverflow.com/questions/21145389
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号