
内存延迟是否受CPU频率的影响?这是内存控制器管理内存电源的结果吗?
我基本上需要一些帮助来解释/证实一些实验结果。
基础理论
在关于DVFS的论文中表达的一个共同观点是,执行时间有片上组件和片外组件。片上组件的执行时间与CPU频率成线性关系,而片外组件则不受影响.
因此,对于CPU绑定应用程序,CPU频率与指令退休率之间存在线性关系.另一方面,对于内存绑定应用程序,缓存经常丢失,DRAM必须频繁访问,这种关系应该是仿射的(其中一个不只是另一个的倍数,还必须添加一个常量)。
实验
我在做实验,研究CPU频率如何影响不同内存有界水平下的指令停用率和执行时间。
我用C编写了一个测试应用程序,它遍历一个链接列表。我实际上创建了一个链接列表,其单个节点的大小等于缓存行的大小(64个字节)。我分配了大量内存,这是缓存行大小的倍数。
链接列表是循环的,因此最后一个元素链接到第一个元素。此外,此链接列表随机遍历分配内存中的缓存行大小的块.在分配的内存中,每个缓存行大小的块都被访问,并且没有任何块被访问超过一次。
由于随机遍历,我认为硬件不可能使用任何预取。基本上,通过遍历列表,您有一个没有跨步模式、没有时间局部性和没有空间局部性的内存访问序列。另外,由于这是一个链接列表,只有在上一次访问完成后才能开始一个内存访问。因此,内存访问不应该是可并行的。
当分配的内存量足够小时,除了初始预热之外,您应该没有缓存丢失。在这种情况下,工作负载是有效的CPU约束和指令退休率非常清楚地与CPU频率。
当分配的内存量足够大(大于LLC)时,您应该丢失缓存。工作负载是内存绑定的,指令退休率不应随着CPU频率的增加而增加。
基本的实验装置类似于这里描述的"Linux "cpufreq“子系统报告的实际CPU频率与CPU频率“。
上面的应用程序会在一段时间内重复运行。在持续时间的开始和结束时,对硬件性能计数器进行采样,以确定在持续时间内退出的指令数量。还测量了持续时间的长度。平均指令退休率是以这两个值之间的比率来衡量的。
使用Linux中的“用户空间”CPU频率调控器,可以在所有可能的CPU频率设置中重复这个实验。另外,还对上述CPU绑定情况和内存绑定情况进行了重复实验。
结果
以下两幅图分别显示CPU绑定案例和内存绑定案例的结果。在x轴上,CPU时钟频率在GHz中指定.在y轴上,指令退休率在(1/ns)中指定.
为重复上述实验设置了一个标记。这一行显示了如果指令退休率以与CPU频率相同的速度增长,并通过最低频率标记时,结果将是什么。
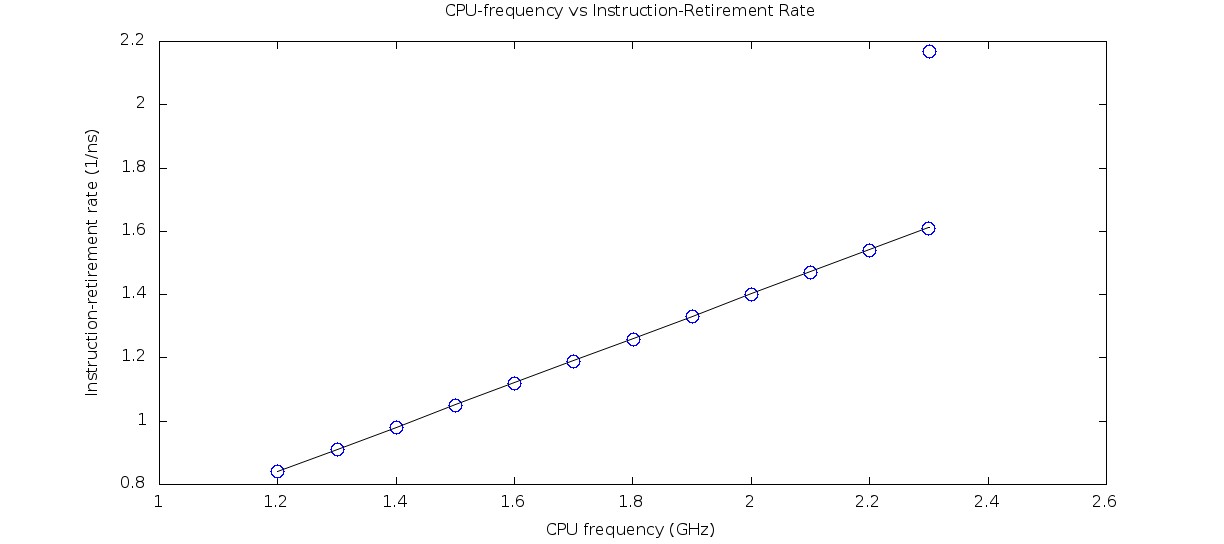
CPU绑定情况的结果。
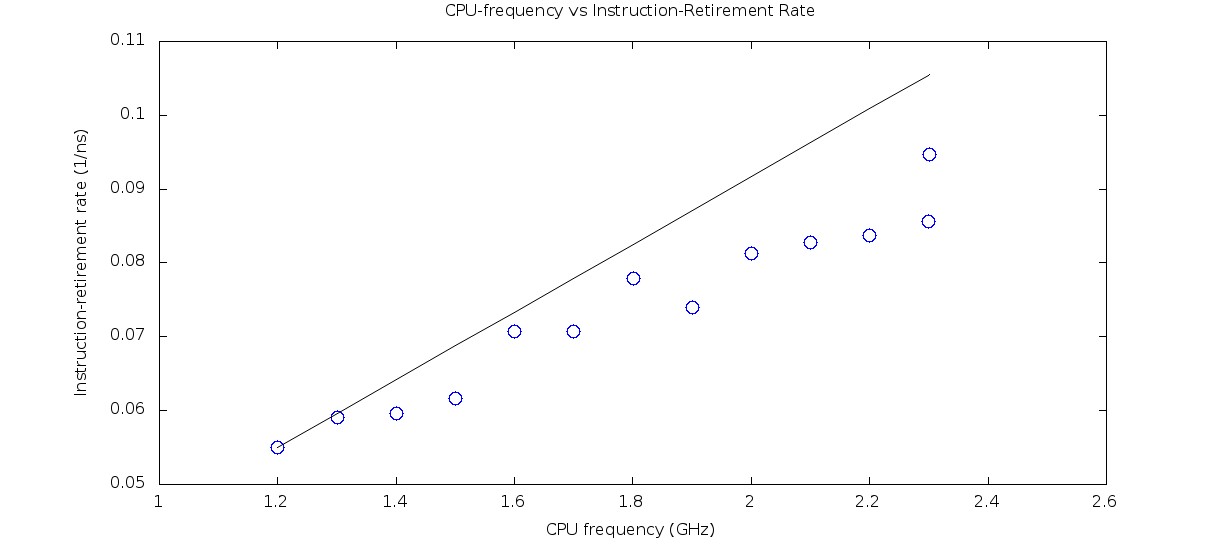
内存绑定情况的结果。
结果对于CPU绑定的情况来说是有意义的,但对于内存绑定的情况则不那么有意义。内存绑定的所有标记都低于预期的行,因为指令退休率不应以与内存绑定应用程序的CPU频率相同的速度增长。标志似乎落在直线上,这也是意料之中的。
然而,随着CPU频率的变化,指令退休率似乎也发生了阶段性变化.
问题
是什么导致指令退休率的步骤变化?我唯一能想到的解释是,随着内存请求速率的变化,内存控制器正在以某种方式改变内存的速度和功耗。(随着指令退休率的提高,内存请求的速率也应该增加。)这解释正确吗?
回答 1
Stack Overflow用户
发布于 2013-12-25 08:06:11
您似乎有您预期的结果-- cpu绑定程序的大致线性趋势,以及内存绑定情况( cpu受影响较小)的浅仿射趋势。您将需要更多的数据来确定它们是否是一致的步骤,或者它们是否是--正如我所怀疑的--主要是随机抖动,这取决于列表的好坏。
cpu时钟会影响总线时钟,这会影响时间等等--不同时钟总线之间的同步一直是硬件设计者的挑战。你的步距是有趣的400 Mhz,但我不会从中得出太多-一般来说,这类东西太复杂和具体-硬件依赖于正确的分析,没有内存控制器使用的‘内部’知识,等等。
(请画出最合适的线条)
https://stackoverflow.com/questions/20667867
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号