
如何只使用Python获取视频flv片段的所有urls?
普通民众观看视频的网址是:XNjM5NDU1OTUy.html
这个视频被分成14个flv片段,其中5个是广告flv。
如果我打开IE11的开发工具,并在观看视频的整个过程中继续捕捉网络流(必须是整个过程,或者服务器没有将所有的视频flv发送到IE11),flv将被IE11捕获,然后我可以复制以下图片显示在红线框中的flv的数据:
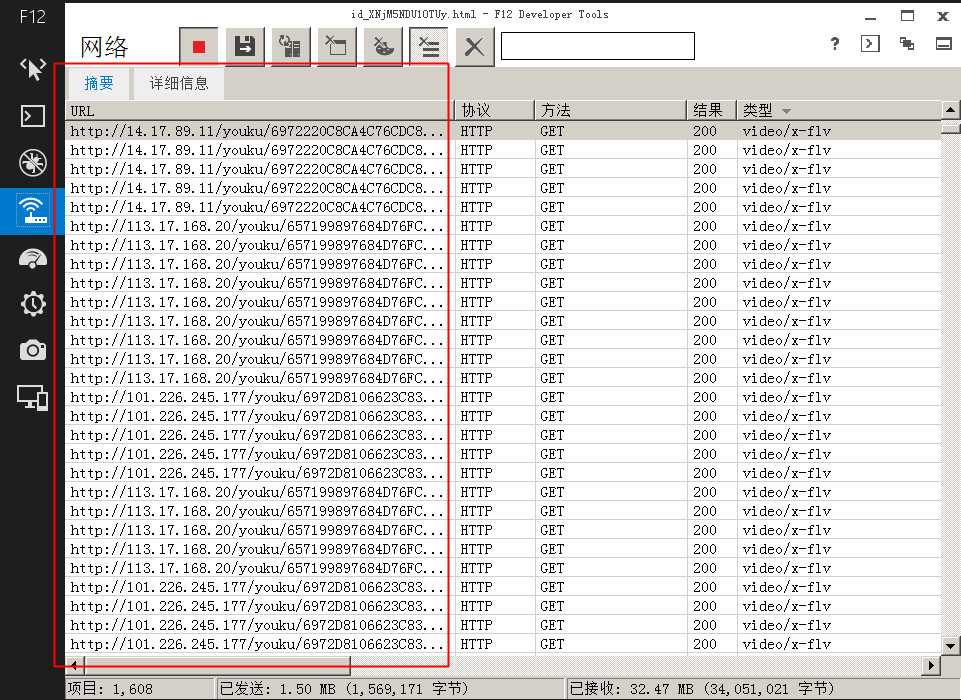
然后,我可以将数据转换成一个url字符串列表,并使用Python下载它们。
但这真的是个麻烦。
我尝试将XNjM5NDU1OTUy.html的源代码与flv匹配,但没有结果。因此,我猜代码中一定有一个函数、一个javascript或其他东西来告诉服务器发送所有的flv。我说的对吗?
所以,
1.如何仅用Python获取视频flv片段的所有urls?
2.我应该学些什么来解决这种问题。
毕竟,使用IE11的开发人员工具,等待视频的整个过程(将近一个小时),将相关数据复制到txt文件中,最后使用Python解析txt文件确实是个麻烦。
提前谢谢。
回答 1
Stack Overflow用户
发布于 2013-12-06 08:53:30
我想你可以从Youtube-dl那里得到一些见解。它是一组用来“下载Youtube视频和更多网站”的python脚本。到他们的下载区,拿全源球。我认为这在某种程度上可能是有用的,至少可以给你一些关于如何处理flv片段的指导。
https://stackoverflow.com/questions/20419518
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号