
一维纹理内存访问比一维全局内存访问快吗?
我正在测量标准和一维存储器访问之间的差异。为此,我创建了两个内核
__global__ void texture1D(float* doarray,int size)
{
int index;
//calculate each thread global index
index=blockIdx.x*blockDim.x+threadIdx.x;
//fetch global memory through texture reference
doarray[index]=tex1Dfetch(texreference,index);
return;
}
__global__ void standard1D(float* diarray, float* doarray, int size)
{
int index;
//calculate each thread global index
index=blockIdx.x*blockDim.x+threadIdx.x;
//fetch global memory through texture reference
doarray[index]= diarray[index];
return;
}然后,我调用eache内核来度量所需的时间:
//copy array from host to device memory
cudaMemcpy(diarray,harray,sizeof(float)*size,cudaMemcpyHostToDevice);
checkCuda( cudaEventCreate(&startEvent) );
checkCuda( cudaEventCreate(&stopEvent) );
checkCuda( cudaEventRecord(startEvent, 0) );
//bind texture reference with linear memory
cudaBindTexture(0,texreference,diarray,sizeof(float)*size);
//execute device kernel
texture1D<<<(int)ceil((float)size/threadSize),threadSize>>>(doarray,size);
//unbind texture reference to free resource
cudaUnbindTexture(texreference);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
//copy result array from device to host memory
cudaMemcpy(horray,doarray,sizeof(float)*size,cudaMemcpyDeviceToHost);
//check result
checkResutl(horray, harray, size);
cudaEvent_t startEvent2, stopEvent2;
checkCuda( cudaEventCreate(&startEvent2) );
checkCuda( cudaEventCreate(&stopEvent2) );
checkCuda( cudaEventRecord(startEvent2, 0) );
standard1D<<<(int)ceil((float)size/threadSize),threadSize>>>(diarray,doarray,size);
checkCuda( cudaEventRecord(stopEvent2, 0) );
checkCuda( cudaEventSynchronize(stopEvent2) );
//copy back to CPU
cudaMemcpy(horray,doarray,sizeof(float)*size,cudaMemcpyDeviceToHost);和打印结果:
float time,time2;
checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) );
checkCuda( cudaEventElapsedTime(&time2, startEvent2, stopEvent2) );
printf("Texture bandwidth (GB/s): %f\n",bytes * 1e-6 / time);
printf("Standard bandwidth (GB/s): %f\n",bytes * 1e-6 / time2);结果是,无论我分配的数组的大小(size),标准带宽总是要高得多。这是应该的还是我在某个时候搞砸了?我对纹理内存访问的理解是,它可以加速全局内存访问。
回答 1
Stack Overflow用户
发布于 2013-11-08 23:38:06
我对全局内存和纹理内存(仅用于缓存目的,而不是用于过滤)进行了比较,用于一维复值函数的插值。
我比较的核心是使用全局内存的4、使用全局内存的2和使用纹理内存的2。它们根据访问复杂值的方式(1 float2或2 floats)进行区分,并在下面报告。我将在某个地方发布完整的Visual 2010,以防有人喜欢批评或执行他自己的测试。
__global__ void linear_interpolation_kernel_function_GPU(float* __restrict__ result_d, const float* __restrict__ data_d, const float* __restrict__ x_out_d, const int M, const int N)
{
int j = threadIdx.x + blockDim.x * blockIdx.x;
if(j<N)
{
float reg_x_out = x_out_d[j/2]+M/2;
int k = __float2int_rz(reg_x_out);
float a = reg_x_out - __int2float_rz(k);
float dk = data_d[2*k+(j&1)];
float dkp1 = data_d[2*k+2+(j&1)];
result_d[j] = a * dkp1 + (-dk * a + dk);
}
}
__global__ void linear_interpolation_kernel_function_GPU_alternative(float2* __restrict__ result_d, const float2* __restrict__ data_d, const float* __restrict__ x_out_d, const int M, const int N)
{
int j = threadIdx.x + blockDim.x * blockIdx.x;
if(j<N)
{
float reg_x_out = x_out_d[j]+M/2;
int k = __float2int_rz(reg_x_out);
float a = reg_x_out - __int2float_rz(k);
float2 dk = data_d[k];
float2 dkp1 = data_d[k+1];
result_d[j].x = a * dkp1.x + (-dk.x * a + dk.x);
result_d[j].y = a * dkp1.y + (-dk.y * a + dk.y);
}
}
__global__ void linear_interpolation_kernel_function_GPU_texture(float2* __restrict__ result_d, const float* __restrict__ x_out_d, const int M, const int N)
{
int j = threadIdx.x + blockDim.x * blockIdx.x;
if(j<N)
{
float reg_x_out = x_out_d[j]+M/2;
int k = __float2int_rz(reg_x_out);
float a = reg_x_out - __int2float_rz(k);
float2 dk = tex1Dfetch(data_d_texture,k);
float2 dkp1 = tex1Dfetch(data_d_texture,k+1);
result_d[j].x = a * dkp1.x + (-dk.x * a + dk.x);
result_d[j].y = a * dkp1.y + (-dk.y * a + dk.y);
}
}
__global__ void linear_interpolation_kernel_function_GPU_texture_alternative(float* __restrict__ result_d, const float* __restrict__ x_out_d, const int M, const int N)
{
int j = threadIdx.x + blockDim.x * blockIdx.x;
if(j<N)
{
float reg_x_out = x_out_d[j/2]+M/4;
int k = __float2int_rz(reg_x_out);
float a = reg_x_out - __int2float_rz(k);
float dk = tex1Dfetch(data_d_texture2,2*k+(j&1));
float dkp1 = tex1Dfetch(data_d_texture2,2*k+2+(j&1));
result_d[j] = a * dkp1 + (-dk * a + dk);
}
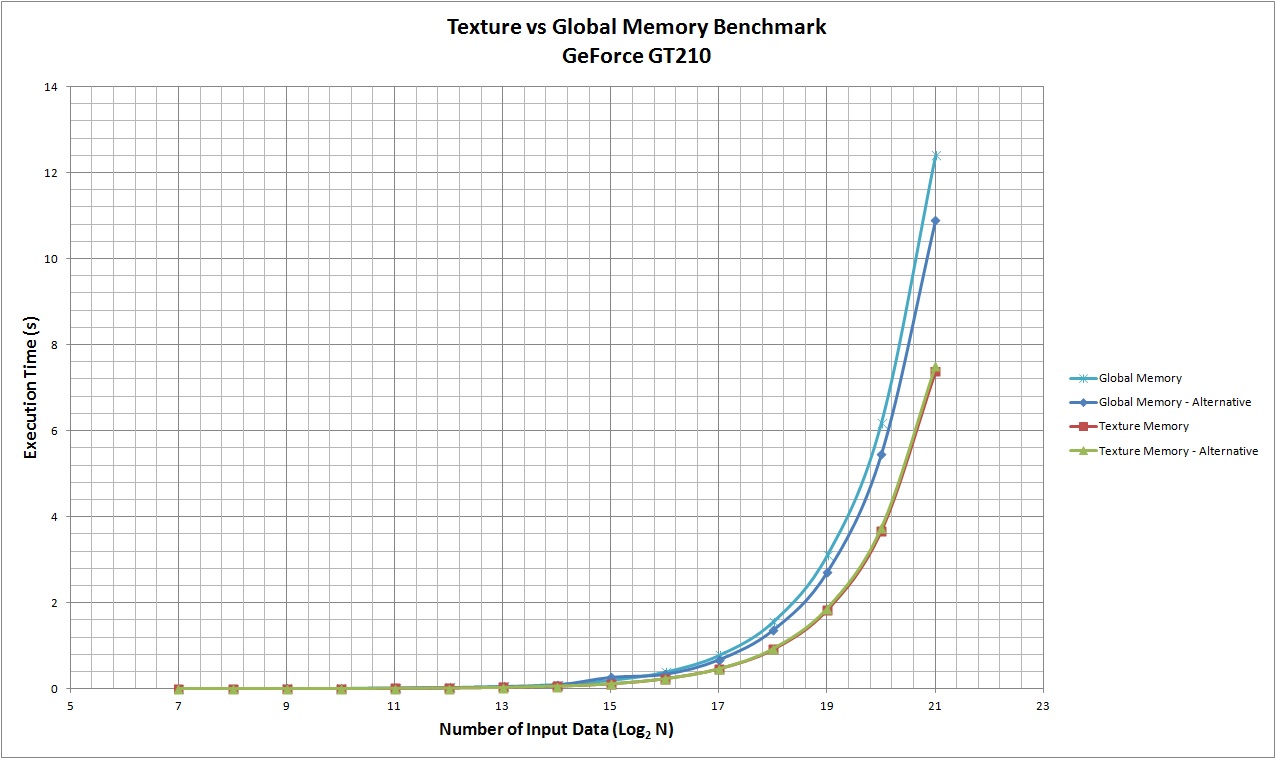
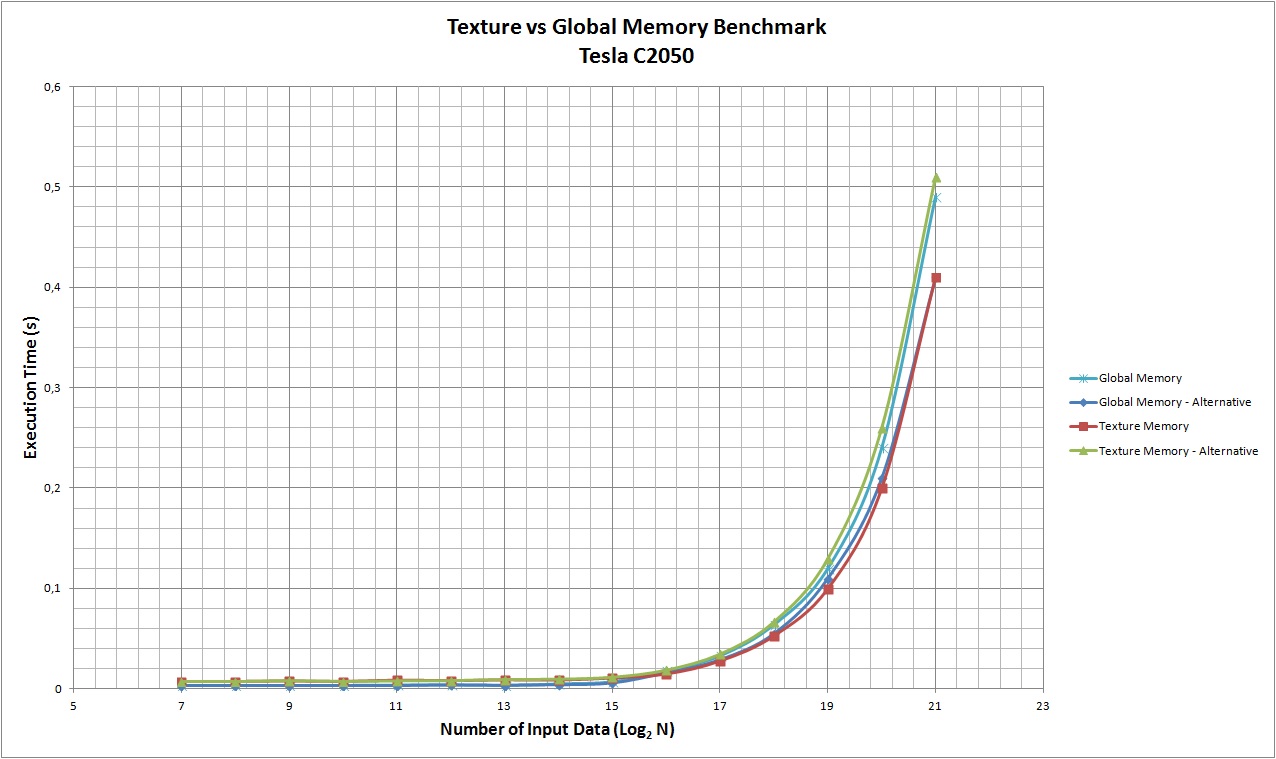
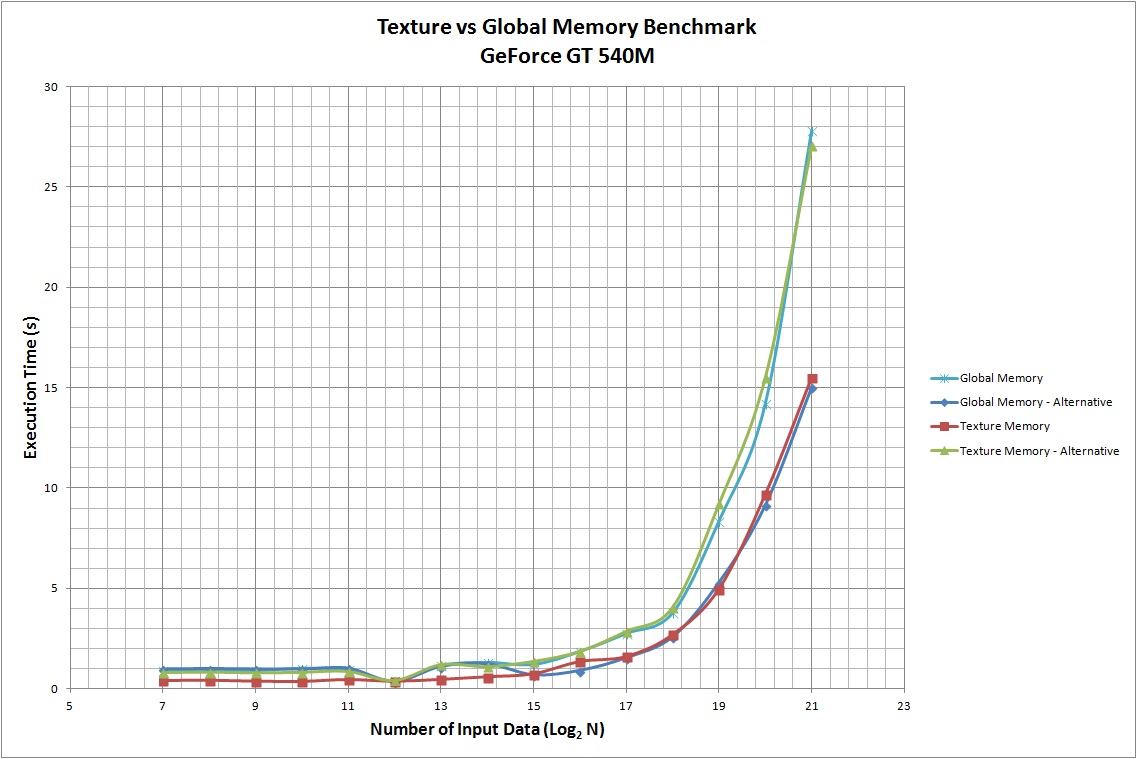
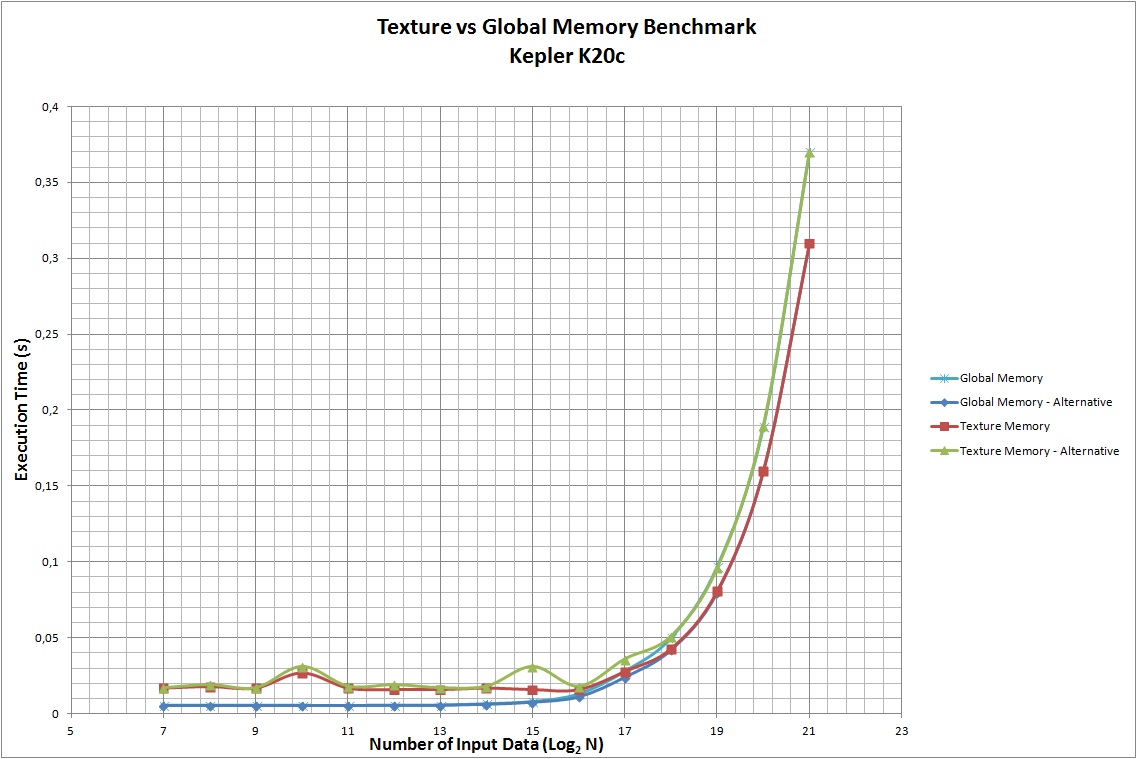
}我考虑了4种不同的GPU,即GeForce GT540M (cc 2.1)、Tesla C2050 (cc 2.0)、开普勒K20c (cc 3.5)和GT210 (cc 1.2)。结果见下表。可以看出,与使用全局内存相比,使用纹理作为缓存具有更老的计算能力,而这两种解决方案对于最新的体系结构来说是相当等效的。
当然,这个例子并不是详尽无遗的,在实践中可能会有其他情况,前者或后者应被优先用于特定的应用。
附注:处理时间以ms为单位,而不是如图标签中所示的s。
https://stackoverflow.com/questions/19860094
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号