
渲染到一维纹理
我正在尝试几种方法来实现一个简单的粒子系统。在这里,我使用乒乓球技术之间的几个纹理,所有附加到一个独特的fbo。
我认为所有绑定/设置都是正确的,因为我看到它使用来自A纹理的数据写入B纹理。
问题是B纹理中只有一个纹理被写入:
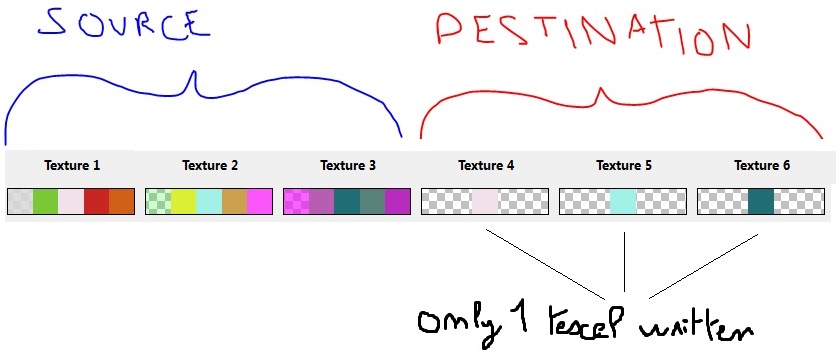
在此图像中,我尝试将纹理从源纹理复制到目标纹理。
让我们来看一下代码:
设置代码
#define NB_PARTICLE 5
GLuint fbo;
GLuint tex[6];
GLuint tex_a[3];
GLuint tex_b[3];
int i;
// 3 textures for position/vitesse/couleur
// we double them for ping-pong so 3 * 2 = 6 textures
glGenTextures(6, tex);
for (i = 0 ; i < 6 ; i++ )
{
glBindTexture(GL_TEXTURE_1D, tex[i]);
glTexImage1D(GL_TEXTURE_1D, 0, GL_RGBA32F, NB_PARTICLE, 0, GL_RGBA, GL_FLOAT, NULL);
glTexParameteri(GL_TEXTURE_1D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_1D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_1D, GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(GL_TEXTURE_1D, GL_TEXTURE_WRAP_T, GL_CLAMP);
}
for (i = 0; i < 3; i++)
{
tex_a[i] = tex[i];
tex_b[i] = tex[i + 3];
}
// Uploads particle data from "a" textures
glBindTexture(GL_TEXTURE_1D, tex_a[0]);
glTexImage1D(GL_TEXTURE_1D, 0, GL_RGBA32F, NB_PARTICLE, 0, GL_RGBA, GL_FLOAT, seed_pos);
glBindTexture(GL_TEXTURE_1D, tex_a[1]);
glTexImage1D(GL_TEXTURE_1D, 0, GL_RGBA32F, NB_PARTICLE, 0, GL_RGBA, GL_FLOAT, seed_vit);
glBindTexture(GL_TEXTURE_1D, tex_a[2]);
glTexImage1D(GL_TEXTURE_1D, 0, GL_RGBA32F, NB_PARTICLE, 0, GL_RGBA, GL_FLOAT, seed_color);
// Create the fbo
glGenFramebuffers(1, &fbo);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, fbo);
// Attach the textures to the corresponding fbo color attachments
int i;
for (i = 0; i < 6; i++)
glFramebufferTexture1D(GL_DRAW_FRAMEBUFFER, GL_COLOR_ATTACHMENT0 + i, GL_TEXTURE_1D, tex[i], 0);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);渲染代码
static int pingpong = 1;
glUseProgram(integratorShader);
glBindVertexArray(0);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, fbo);
// Set the input textures to be the "a" textures
int i;
for (i = 0 ; i < 3 ; i++ )
{
glActiveTexture(GL_TEXTURE0 + i);
glBindTexture(GL_TEXTURE_1D, tex_a[i]);
}
// Set the draw buffers to be the "b" textures attachments
glDrawBuffers(3, GL_COLOR_ATTACHMENT0 + (pingpong * 3) );
glViewport(0, 0, NB_PARTICLE, 1);
glDrawArrays(GL_POINTS, 0, NB_PARTICLE);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glUseProgram(0);
// A became B and B became A
swapArray(tex_a, tex_b, 3);
pingpong++;
pingpong %= 2;顶点着色机
#version 430
void main() {
gl_Position = vec4(gl_VertexID, 0, 0, 1);
}破片着色机
#version 430
// binding = texture unit
layout (binding = 0) uniform sampler1D position_texture;
layout (binding = 1) uniform sampler1D vitesse_texture;
layout (binding = 2) uniform sampler1D couleur_texture;
// location = index in the "drawBuffers" array
layout (location = 0) out vec4 position_texel;
layout (location = 1) out vec4 vitesse_texel;
layout (location = 2) out vec4 couleur_texel;
void main() {
vec4 old_position_texel = texelFetch(position_texture, int(gl_FragCoord.x), 0);
vec4 old_vitesse_texel = texelFetch(vitesse_texture, int(gl_FragCoord.x), 0);
vec4 old_couleur_texel = texelFetch(couleur_texture, int(gl_FragCoord.x), 0);
position_texel = old_position_texel;
vitesse_texel = old_vitesse_texel;
couleur_texel = old_couleur_texel;
}由于我正在使用一维纹理,我认为我需要发送的唯一数据是一个索引,我完全可以使用gl_VertexID实现这一点。这就是为什么我要发送0属性数据。
我认为问题在于我设置gl_FragCoord的方式(遗憾的是,它是我唯一不能调试的变量:( )
回答 1
Stack Overflow用户
发布于 2013-11-07 16:53:29
问题是如何调用着色器。您基本上已经建立了一个标准的You片段着色管道,处理输入纹理的每个纹理,并将结果写入输出纹理中的相应纹理。但是,您调用这个GPGPU管道的方式,即您呈现几何图形的方式,是完全垃圾的。所有其他的东西,特别是你的片段着色器和你使用gl_FragCoord的方式都是很好的。
似乎您混淆了计算传递(您想要计算粒子位置)和绘图传递(您想要渲染粒子,可能是点)。但在这个GPGPU阶段,绝对没有必要渲染N点,因为你在顶点着色器中没有做任何有用的事情。您所要做的就是为框架缓冲区的每个像素生成一个片段。但不管怎么说,这已经为你实现了。当您想要在“普通”图形应用程序中绘制三角形时,您不会自己将三角形细分为像素,并将其绘制为GL_POINTS,对吗?它失败的确切错误是您奇怪地使用gl_VertexID作为坐标。由于您不使用任何转换,输出顶点坐标应该位于-1,1-框中,其他一切都会被剪裁掉。但是你的点在位置(0,0),(1,0),(2,0),.,所以它们不密集地覆盖框架缓冲区,只绘制(0,0)的点,这正是你看到的中心像素( (1,0)的点可能也因为四舍五入而被剪掉)。
所以你要做的就是画一个覆盖整个框架缓冲区的四角体。这意味着,如果没有任何转换,它应该覆盖整个剪辑空间,从而覆盖-1,1-平方(实际上,当使用一个只有一个像素高的帧缓冲区时,一条线甚至可以)。然后,光栅化器生成您需要的所有片段。在不使用任何属性的情况下,您仍然可以通过只呈现一个四角体(而不激活任何属性)来实现这一点:
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);然后使用顶点ID选择四角的适当角:
const vec2 corners[4] = {
vec2(-1.0, 1.0), vec2(-1.0, -1.0), vec2(1.0, 1.0), vec2(1.0, -1.0) };
void main()
{
gl_Position = vec4(corners[gl_VertexID], 0.0, 1.0);
}然后,这将为每个像素生成一个片段,其他一切都应该正常工作。
顺便提一句,我不确定你是否真的想要一维纹理,因为与缓冲区相比,一维纹理有相当严格的尺寸限制。您可以使用2D纹理,这不会改变当前处理中的任何内容(尽管在实际绘制粒子时可能需要一些索引魔术)。
事实上,当您已经使用了OpenGL 4.3时,执行类似粒子引擎这样的GPGPU任务的更自然的方法是一个计算着色器。通过这种方式,您可以将粒子数据存储在缓冲区对象中,直接处理那些使用计算着色器的对象,而不需要将它们打包到纹理中(因为您可能希望稍后呈现它们,因此需要在顶点着色器中读取纹理),而不需要滥用用于计算任务的图形管道,也不需要任何乒乓存储(只需在现有的缓冲器上工作)。
https://stackoverflow.com/questions/19839442
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号