
子矩阵计算
我要计算矩阵的两个子矩阵之间的成对距离。例如,我有一个矩阵A (MxN)和矩阵B1 (mxn)和B2 (kxt)的两个块。更具体地说,我希望计算B1(1,1)元素与B2所有其他元素的距离,并对所有B1元素执行此过程。更清楚的是,B1和B2可能不是矩阵的紧密部分,基本上,我知道的信息是矩阵A上B1和B2元素的坐标。
for(int i = 0; i < nRowsCoordsB1 ; i++ ){//nRows of B1
for(int j = 0; j < nRowsCoordsB2 ; j++ ){//nRows of B2
//CoordsofB1 is a nRowsB1x2 matrix that contains the element coordinates of the B1 sub matrix
a_x = CoordsofB1[ i ]; //take the x coord of the corresponding row i
a_y = CoordsofB1[ i + nRowsCoordsB1 ]; //take the y coord of the corresponding row
b_x = CoordsofB2[ j ];
b_y = CoordsofB2[ j + nRowsCoordsB2 ];
int element1 = A[ a_x + a_y*nRowsofA ];
int element2 = A[ b_x + b_y*nRowsofA ] ;
sum +=abs( element1 - element2 ) ;
}
}
*Output = sum/(float)(numberOfElementsofB1*numberOfElementsofB2); 现在我想用CUDA来加速计算),因为我是Cuda的新手,所以我发现它有点复杂。从现在起,我想我已经理解了在矩阵级别分配块线程的逻辑,但是在这里,我有两个不同大小的矩阵,CoordsofB1和CoordsofB2,这使我有点困惑于如何访问它们,获取坐标并在孔矩阵中使用它们。我认为我们应该在A中使用约束,但我没有一个清晰的想法。
还有一个事实,在for循环的末尾,和被用一个量除以,这使我对我们将在cuda翻译代码中组合的人感到困惑。
任何建议-片段-例子-参考会很好。
PS:我之所以使用列-主要排序是因为代码是在matlab中计算的。
更新:我们可以分配大小相等于最大子矩阵B1或B2大小的线程块,并使用正确的条件与它们一起工作吗?我评论最后一行,因为我不知道该如何处理它。有什么评论吗?
int r = blockDim.x * blockIdx.x + threadIdx.x; // rows
if( r < nRowsCoordsB1 ){
a_x = CoordsofB1[ r ];
a_y = CoordsofB1[ r + nRowsCoordsB1 ];
if( r < nRowsCoordsB2 ;){
b_x = CoordsofB2[ r ];
b_y = CoordsofB2[ r + nRowsCoordsB2 ];
int element1 = A[ a_x + a_y*nRowsofA ];
int element2 = A[ b_x + b_y*nRowsofA ] ;
sum +=abs( element1 - element2 ) ;
}
}
//*Output = sum/(float)(numberOfElementsofB1*numberOfElementsofB2); 这里有个素描
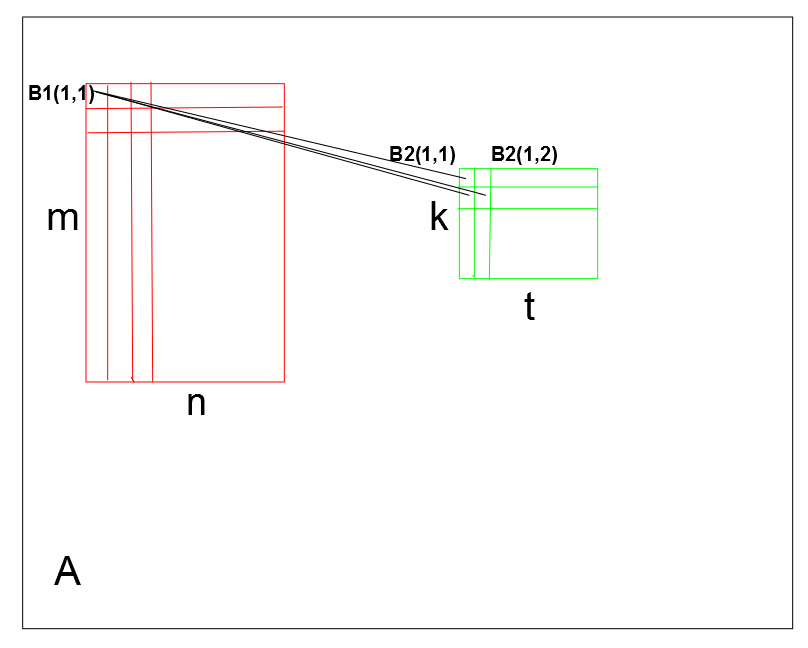
我有B1和B2中每个元素的坐标,我想计算
[ (B1(1,1) - B2(1,1)) + (B1(1,1) - B2(1,2)) +.+ (B1(1,1) - B2(:,:) ] +
[ (B1(1,2) - B2(1,1)) + (B1(1,2) - B2(1,2)) +.+ (B1(1,2) - B2(:,:) ] +
[ (:,:) - B2(1,1)) + (B1(:,:) - B2(1,2)) +.+ (B1(:,:) - B2(:,:) ]。
回答 2
Stack Overflow用户
发布于 2013-10-25 13:30:30
如果我正确理解它,你想要做的事情可以用下面的matlab代码来写。
rep_B1 = repmat(B1(:), 1, length(B2(:)) );
rep_B2 = repmat(B2(:)', length(B1(:), 1) );
absdiff_B1B2 = abs(rep_B1 - repB2);
Result = mean( absdiff_B1B2(:) );您将注意到,在缩减之前,有一个大小为absdiff_B1B2 x length(B2(:))的矩阵,即m*n x k*t (如果在一个CUDA内核中实现上述代码,则该矩阵永远不会存储到全局mem中)。您可以将该矩阵划分为16x16个子矩阵,并使用每个子矩阵使用一个256个线程块将工作负载分解为GPU。
另一方面,你可以利用推力让你的生活更轻松。
更新
由于B1和B2是A的子矩阵,所以可以首先使用cudaMemcpy2D()将它们复制到线性空间,然后使用内核构造矩阵absdiff_B1B2,然后将矩阵absdiff_B1B2缩减。
对于最后的规范化操作(代码的最后一行),可以在CPU上完成。
下面的代码使用推力来演示如何在单个内核中构造和减少矩阵absdiff_B1B2。但是,您会发现构造过程没有使用共享内存,也没有进行优化。进一步优化使用共享mem将提高性能。
#include <thrust/device_vector.h>
#include <thrust/inner_product.h>
#include <thrust/iterator/permutation_iterator.h>
#include <thrust/iterator/transform_iterator.h>
#include <thrust/iterator/counting_iterator.h>
template<typename T>
struct abs_diff
{
inline __host__ __device__ T operator()(const T& x, const T& y)
{
return abs(x - y);
}
};
int main()
{
using namespace thrust::placeholders;
const int m = 98;
const int n = 87;
int k = 76;
int t = 65;
double result;
thrust::device_vector<double> B1(m * n, 1.0);
thrust::device_vector<double> B2(k * t, 2.0);
result = thrust::inner_product(
thrust::make_permutation_iterator(
B1.begin(),
thrust::make_transform_iterator(
thrust::make_counting_iterator(0),
_1 % (m * n))),
thrust::make_permutation_iterator(
B1.begin(),
thrust::make_transform_iterator(
thrust::make_counting_iterator(0),
_1 % (m * n))) + (m * n * k * t),
thrust::make_permutation_iterator(
B2.begin(),
thrust::make_transform_iterator(
thrust::make_counting_iterator(0),
_1 / (m * n))),
0.0,
thrust::plus<double>(),
abs_diff<double>());
result /= m * n * k * t;
std::cout << result << std::endl;
return 0;
}Stack Overflow用户
发布于 2013-10-25 21:52:14
也许下面使用2D线程网格的解决方案可以替代Eric使用推力来对问题有更深入的了解。
下面的代码片段只是为了说明这个概念。这是一个未经测试的代码。
二维网格
定义大小为partial_distances的nRowsCoordsB1 X nRowsCoordsB2矩阵,该矩阵将包含B1和B2元素之间所有涉及的绝对值差异。在main文件中
__global__ void distance_calculator(int* partial_distances, int* CoordsofB1, int* CoordsofB2, int nRowsCoordsB1, int nRowsCoordsB2) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
int j = blockDim.y * blockIdx.y + threadIdx.y;
int a_x = CoordsofB1[i];
int a_y = CoordsofB1[i+nRowsCoordsB1];
int b_x = CoordsofB2[j];
int b_y = CoordsofB2[j+nRowsCoordsB2];
partial_distances[j*nRowsCoordsB1+i] = abs(A[a_x+a_y*nRowsofA]-A[b_x+b_y*nRowsofA]);
}
int iDivUp(int a, int b) { return (a % b != 0) ? (a / b + 1) : (a / b); }
#define BLOCKSIZE 32
int main() {
int* partial_distances; cudaMalloc((void**)&partial_distances,nRowsCoordsB1*nRowsCoordsB2*sizeof(int));
dim3 BlocSize(BLOCKSIZE,BLOCKSIZE);
dim3 GridSize;
GridSize.x = iDivUp(nRowsCoordsB1,BLOCKSIZE);
GridSize.y = iDivUp(nRowsCoordsB2,BLOCKSIZE);
distance_calculator<<<GridSize,BlockSize>>>(partial_distances,CoordsofB1,CoordsofB2,nRowsCoordsB1,nRowsCoordsB2);
REDUCTION_STEP
}REDUCTION_STEP可以作为对一维缩减内核的迭代调用来实现,以总结与B1特定元素相对应的所有元素。
另一种选择是使用动态并行来直接调用内核中的还原例程,但这是一个不适合您使用的卡的选项。
https://stackoverflow.com/questions/19588565
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号