
查找blob中最长的blob前缀
我试图在C++中生成/获得一个有效的实现,以解决以下问题:
我不得不使用blob1 (const *data,size_t长度),我将它们称为"blob1“和"blob2”。现在,我喜欢在"blob2“中获得最长的前缀"blob1”。如果最长的前缀是"blob1“中的多次前缀,我希望得到索引最大的前缀。
这里有一个示例( blobs在这里只是ASCII-字符串,因此更容易阅读该示例):
blob1 = HELLO LOOO HELOO LOOO LOO JU
blob2 = LOOO TUS
以下是blob2的所有有效前缀:
{ L,LO,LOO,LOOO,LOOO,LOOO T,LOOO TU,LOOO TUS }
blob2在blob1中最长的前缀是LOOO。它有两次:HELLO *LOOO *HELOO *LOOO *LOO JU
所以我想得到第二个索引,它是6,前缀的长度,也就是4。
不幸的是,blob1和blob2更改了很多次,因此创建树或其他复杂结构可能很慢。
你知道解决这个问题的好算法吗?
谢谢。
干杯凯文
回答 1
Stack Overflow用户
发布于 2013-10-22 23:12:54
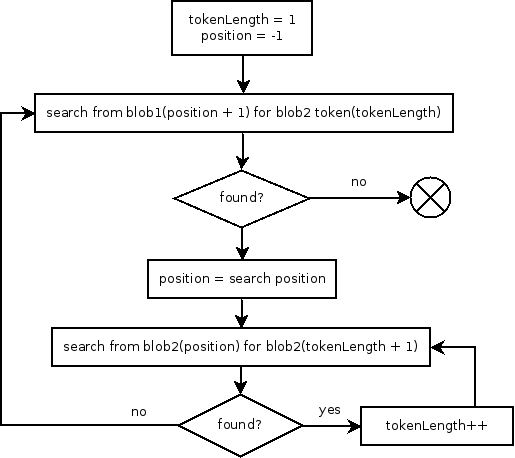
我不知道这是否是解决这个问题的最佳算法(我肯定,这不是),但是,我想这是一个很好的算法。这个想法很简单,从blob2在blob1中搜索最低令牌开始。当您找到匹配时,试着看看是否可以在此位置匹配较大的令牌。如果这是正确的,更新您的令牌长度。
继续搜索,从您的最后一站,但此时,使用更新的令牌长度从blob2搜索。当您找到匹配时,试着看看是否可以在此位置匹配较大的令牌。如果这是正确的,更新您的令牌长度。重复前面的步骤,直到缓冲区结束。
Bellow是一个简单的流动图,试图解释这个算法,然后,一个简单的完整程序,显示一个实现。
#include <algorithm>
#include <vector>
#include <iostream>
/////////////////////0123456789012345678901234567
const char str1[] = "HELLO LOOO HELOO LOOO LOO JU";
const char str2[] = "LOOO TUS";
int main()
{
std::vector<char> blob1(strlen(str1));
std::vector<char> blob2(strlen(str2));
blob1.reserve(30);
blob2.reserve(30);
std::copy(str1, str1+strlen(str1), blob1.begin());
std::copy(str2, str2+strlen(str2), blob2.begin());
auto next = blob1.begin();
auto tokenLength = 1;
auto position = -1;
while ( std::next(next, tokenLength) < blob1.end() ) {
auto current = std::search(next,
blob1.end(),
blob2.begin(),
std::next(blob2.begin(), tokenLength));
if (current == blob1.end() )
break;
position = std::distance(blob1.begin(), current);
next = std::next(current, 1);
for (auto i = tokenLength; std::next(blob2.begin(), i) < blob2.end(); ++i) {
auto x = std::search(std::next(current, i),
std::next(current, i + 1),
std::next(blob2.begin(), i),
std::next(blob2.begin(), i + 1));
if ( x != std::next(current, i) )
break;
++tokenLength;
}
}
std::cout << "Index: " << position << ", length: " << tokenLength << std::endl;
}https://stackoverflow.com/questions/19526968
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号