
简化循环计算
考虑以下向量x
> 1:9
[1] 1 2 3 4 5 6 7 8 9并考虑以下投入:
start = 10
pmt = 2这就是我想要实现的结果(让我们调用生成的向量res) (显示的是实际公式)。注意,结果是向量,而不是数据。我刚刚展示了它的二维。
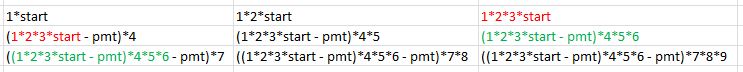
换句话说,要获得res,您可以通过df的每个单元格的累积积获得多个start,直到相应的单元格为止。
当向量索引为4或7时,开始值将被更新。
这就是我所尝试的:
for(i in 1:9) {
res[i] = start * cumprod(df[k:i])[i]
if(i %% 3 == 0) {
start = res[i] - pmt
k = k + 3
} else {
start = res[i]
}
}
}为了把这个问题放在背景中,想象一下你的起始价值是10美元,你想在9个月内投资它。但是,您希望在每3个月结束时(即在第4个月开始,第7个月,.)进行提取。向量x表示返回的随机值。因此,在第4个月开始时,您的起始值是start*1*2*3 减去提取pmt。
这里的目的是计算9月底的财富价值。
问题是,在现实中,i= 200 (200个月),我需要对10,000个不同的向量x重做这个计算。因此,在上面的代码上循环10,000次要花费很长时间才能执行!
你对如何更有效地计算这个问题有什么建议吗?我希望这个解释不要太混乱!
谢谢!
回答 2
Stack Overflow用户
发布于 2013-10-17 19:55:26
如果您将res的公式作为迭代公式计算出来,那么编写一个可以给Reduce的函数就更容易了。这里是一个简单的循环
x <- 1:9
start <- 10
pmt <- 2
res <- numeric(length(x))
res[1] <- x[1] * start
for (i in seq_along(x)[-1]) {
res[i] <- (res[i-1] - (pmt * (!(i%%4) || !(i%%7)))) * x[i]
}如果要将其编写为Reduce函数,则如下所示
Reduce(function(r, i) {
(r - (pmt * (!(i%%4) || !(i%%7)))) * x[i]
},
seq_along(x),
init = start,
accumulate = TRUE)[-1]开始值和删除结果的第一个元素有一些奇怪之处,因为初始值的处理方式(而且迭代是在索引之上,而不是值,因为必须对索引进行比较)。这里的循环可能更容易理解。
Stack Overflow用户
发布于 2013-10-17 20:18:44
我知道你提到它是1d,但我认为它很好用,你可以很容易地把它转换成一维-
start = 10
pmt = 2
library(data.table)
dt <- data.table(
month = 1:13
)
dt[,principalgrown := start*cumprod(month)]
#explained below#######
dt[,interestlost := 0]
for(i in seq(from = 4, to = (dim(dt)[1]), by = 3))
{
dt[month >= i,interestlost := interestlost + (prod(i:month)), by = month]
}
#######################
dt[,finalamount := principalgrown - (pmt*interestlost)]#s中的部分就是诀窍。当您将月份值计算为((1*2*3*start - pmt)*4*5*6 - pmt) * 7时,我将其计算为1*2*3*4*5*6*7*start - 4*5*6*7*pmt - 7*pmt。1*2*3*4*5*6*7*start是principalgrown,- 4*5*6*7*pmt - 7*pmt是-(pmt*interestlost)
https://stackoverflow.com/questions/19435155
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号