
多态类SQL数据库表结构
我有一些表具有不同的结构,但包含相同的数据(在示例中是名称和姓氏)。
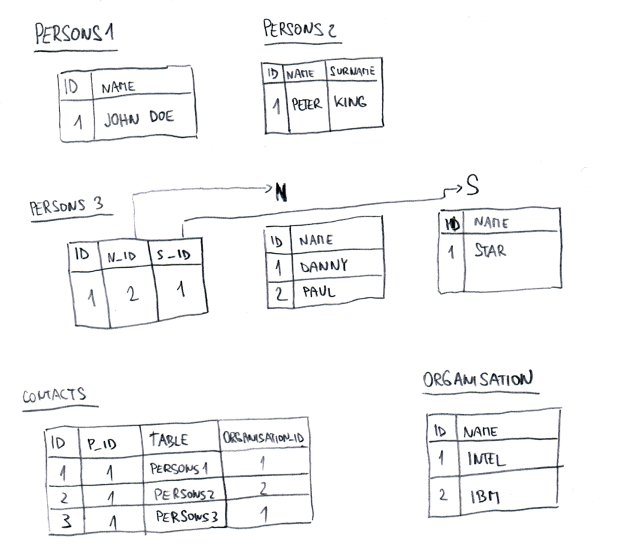
编辑:演示结构小提琴- http://sqlfiddle.com/#!2/cce568
然而,现在我需要创建一些集体表来存储这些信息+一些更多的细节(如日期时间、公司名称、职位等)。根据剩余字段的上下文,这个集体表可以包含多个实体。
请问这张集体桌子有什么储存图案吗?根据Bill的帖子(https://stackoverflow.com/a/562030/1092627),我可以将所有这些表连接到一个表中,但是如果我需要将一些信息直接添加到这个表中,该怎么办呢?
提前谢谢你的意见。
回答 1
Stack Overflow用户
发布于 2013-09-30 13:25:14
Craig的书“使用UML与模式”描述了这个问题的3种常见解决方案。
您的示例没有什么特别的帮助--在数据库中有3种不同的管理人名的方法是没有逻辑的(尽管由于数据导入/导出异常,这种情况经常发生)。
但是,"person“实体很常见,它可能是雇员(使用employee_id)、联系人(具有指向prospects表的链接)或客户(具有customer_id和指向orders表的链接)。
在拉尔曼的书中,他给出了三个解决方案。
在这里,使用一个表来统治所有,您可以创建一个包含所有已知列的表。这将创建一个混乱的表,并将知道将每个子类持久化的规则推入应用程序层的责任--数据库不会强制要求客户拥有customer_id。然而,它使连接变得更加容易--任何需要链接到person的表都可以,嗯,链接到person表。
超类表--它通过将公共属性提取到单个表(例如"person“)中来清理事物,并将子类特定的字段推入子类表中。因此,您可能有"person“作为超类表,"contact”、"employee“和"customer”表具有特定的子类数据。子类表有一个"person_id“列来链接回超类表。这更复杂--在检索数据时通常需要一个额外的联接--但也不太容易出错--您不能意外地用错误来编写"employee“的无效属性。
表每个子类--这就是您所描述的。它在数据模型中引入了相当多的重复,而且通常有条件联接--“如果person type =y,在表x上联接”,这会使数据访问代码变得很棘手。
https://stackoverflow.com/questions/19093031
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号