
如何在没有拥挤图像的情况下使用pytagcloud构建干净的单词云- Python
在一个上一个问题,中,我问社区如何计算一个句子中每一个连续两个单词的频率,我得到了一个很好的答案!现在,我正尝试使用pytagcloud包从结果中构建一个单词云。
我的问题是,制作的图片很拥挤,文字在一起。如果有一个函数来分离单词并使它们具有可读性,或者在python中是否有其他方法来实现这些功能,您可以知道吗?
谢谢!
我的代码如下。这是我用来测试的文本的链接,我尝试使用较少的单词组合,但这并没有改变图片中文本的拥挤性。
我还添加了几个函数,比如播放“布局”、“大小”和"fontname='Lobster‘和fontzoom=1“,但它们都没有给出最佳结果,这是一个干净的单词云图,其中单词并不拥挤。
import operator
import urllib2
from roundup.backends.indexer_common import STOPWORDS
import requests, collections, bs4
Data = "TEXT FROM The link above- TEXT file"
two_words = [' '.join(ws) for ws in zip(Data, Data[1:])]
wordscount = {w:f for w, f in Counter(two_words).most_common() if f > 12}
sorted_wordscount = sorted(wordscount.iteritems(), key=operator.itemgetter(1))
print sorted_wordscount;
from pytagcloud import create_tag_image, create_html_data, make_tags, LAYOUT_HORIZONTAL, LAYOUTS, LAYOUT_MIX, LAYOUT_VERTICAL, LAYOUT_MOST_HORIZONTAL, LAYOUT_MOST_VERTICAL
from pytagcloud.colors import COLOR_SCHEMES
from pytagcloud.lang.counter import get_tag_counts
create_tag_image(make_tags(sorted_wordscount), 'filename.png', size=(1300,1150), background=(0, 0, 0, 255), layout=LAYOUT_MIX, fontname='Molengo', rectangular=True)这是我得到的输出结果的一个例子:这里
最佳结果将类似于这里图像中的一幅。
回答 2
Stack Overflow用户
发布于 2013-10-03 00:17:03
您正在按升序而不是降序对标记进行排序,这可能是pytagcloud所期望的。应将排序行更改为:
sorted_wordscount = sorted(wordscount.iteritems(), key=operator.itemgetter(1),reverse=True)修复后,关键参数是maxsize in make_tags:
create_tag_image(make_tags(sorted_wordscount[:],maxsize=200), 'filename.png', size=(1300,1150), background=(0, 0, 0, 255), layout=LAYOUT_MIX, fontname='Molengo', rectangular=True)如果我正确理解,这将设置最大字体大小(以最高频率标记的字体大小),并计算与此相关的所有其他大小。影响字符串分布方式的另一个参数是窗口的大小。
您必须使用这些参数。
考虑到库函数get_tag_counts所做的不仅仅是返回频率:它还过滤普通单词,应用小写,并且通常应该比简单的排序提供更好的标记分布,就像您正在做的那样。
通过这些更改,您应该得到如下内容(通过get_tag_counts在文章中链接的文件(在1000x1000窗口中获取maxsize=260并将其限制在前50个标记中):
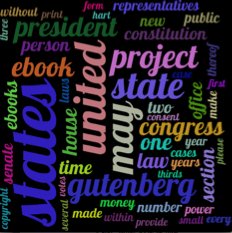
编辑--根据请求,创建上述图像的代码:
import operator
import os
import urllib2
from roundup.backends.indexer_common import STOPWORDS
import requests, collections, bs4
with open("./const11.txt") as file:
Data1 = file.read().lower()
Data = Data1.split()
two_words = [' '.join(ws) for ws in zip(Data, Data[1:])]
wordscount = {w:f for w, f in collections.Counter(two_words).most_common() if f > 5}
sorted_wordscount = sorted(wordscount.iteritems(), key=operator.itemgetter(1),reverse=True)
from pytagcloud import create_tag_image, create_html_data, make_tags, LAYOUT_HORIZONTAL, LAYOUTS, LAYOUT_MIX, LAYOUT_VERTICAL, LAYOUT_MOST_HORIZONTAL, LAYOUT_MOST_VERTICAL
from pytagcloud.colors import COLOR_SCHEMES
from pytagcloud.lang.counter import get_tag_counts
tags = make_tags(get_tag_counts(Data1)[:50],maxsize=260)
create_tag_image(tags,'filename.png', size=(1000,1000), background=(0, 0, 0, 255), layout=LAYOUT_MIX, fontname='Lobster', rectangular=True)`使用python 2.7.5,在Ubuntu13.04上安装了apt,其余的软件包都安装了pip。“ant11.txt”是在问题中链接的文本文件。
Stack Overflow用户
发布于 2013-10-02 20:46:17
编辑:虽然在我的答案中引用的TAG_PADDING参数在某些情况下可能是有意义的,但vinaut的答案显然是更好的开始。
从.py的角度来看,TAG_PADDING可能是控制单词间距的参数。
因为它在源代码中被设置为一个文字值,并且在一些地方被引用,所以您必须将源代码修改为更适合您的参数(并重新打包/重新安装),或者将源代码复制到您自己的项目中并相应地修改它。
https://stackoverflow.com/questions/18974437
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号