
DirectX 11,将像素着色器组合起来以防止瓶颈
我试图用GPU实现一个复杂的算法。唯一的问题是HW限制,最大可用的功能级别是9_3。
算法基本上是两幅图像的“立体声匹配”-like算法。由于上述限制,所有计算只能在顶点/像素着色器中执行(没有可用的计算API )。顶点着色器在这里是相当无用的,所以我认为它们是通过顶点着色器。
让我简短地描述一下算法:
- 获取两幅图像并计算成本体积图(基本上将RGB转换为灰度->,用D翻译右图像并从左侧图像减去)。对于产生Texture3D的不同D,这一步骤重复大约20次。 问题:,我不能简单地创建一个像素着色器,它可以一次计算这20个重复,因为像素着色器的大小限制(最大值)。在C++中,我不得不在一个循环中调用(),这个循环不必要地涉及到CPU,而所有操作都是在相同的两个映像上完成的--在我看来,这里似乎有一个瓶颈--。我知道有多个渲染目标,但是:有最大值。8个目标(我需要20+),如果我想要在一个象素着色器中生成8个结果,我就超过了它的大小限制(我的HW的512个算法)。
- 然后,我需要计算每一个计算出的纹理框过滤器的窗口,其中r> 9。 这里的另一个问题是:,因为窗口太大,我需要将框过滤分成两个像素阴影(分别是垂直方向和水平方向),因为循环展开阶段会产生非常长的代码。手动实现这些循环不会有帮助,因为它仍然会创建大像素着色器。因此,这里的另一个瓶颈是- CPU需要将结果从临时纹理(V的结果)传递到第二次pass (H pass)。
- 在下一步,对第一步和第二步的每对结果进行一些算术运算。 我还没有达到我的开发,所以不知道是什么样的瓶颈在这里等待着我。
- 然后,根据步骤3中的像素值,对每个像素采取最小D(第一步参数值)。 ..。与步骤3相同。
这里基本上是非常简单的图表,显示了我当前的实现(不包括步骤3和步骤4)。
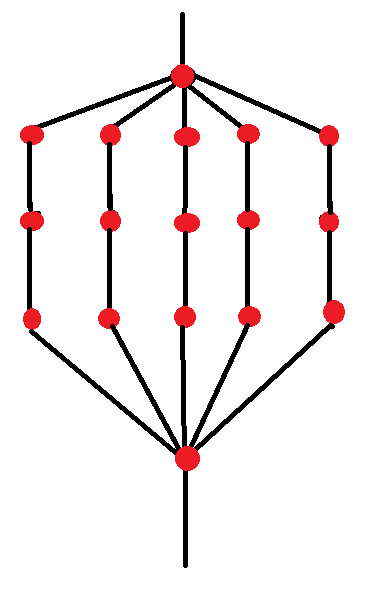
红色点/圆圈/任何临时缓冲区(纹理),其中存储部分结果,并在每一个红色点CPU参与。
问题1:难道不可能让GPU知道如何在不涉及CPU和导致瓶颈的情况下从底层执行每个分支表单吗?也就是说,在一次编程的图形管道序列,然后让GPU做它的工作。
还有一个关于渲染到纹理的问题:所有纹理是否一直驻留在GPU内存中,甚至在绘制()方法调用和像素/顶点着色器切换之间?或者正在发生从GPU到CPU的传输..。因为这可能是导致瓶颈的另一个问题。
任何帮助都将不胜感激!
提前谢谢你。
向你问好,卢卡兹
回答 1
Stack Overflow用户
发布于 2013-09-23 15:36:43
在像素着色器中编写计算算法是非常困难的。为9_3目标编写这样的算法是不可能的。太多限制了。但是我想我知道怎么解决你的问题了。
1.着色重复
首先,不清楚,你在这里所谓的“瓶颈”是什么。是的,理论上,吸引调用for循环是一种性能损失。但会不会是瓶颈呢?您的应用程序真的会在这里失去性能吗?多少钱?只有分析器(CPU和GPU)才能回答。但是要运行它,您必须首先完成算法(第3和第4阶段)。因此,我最好坚持当前的解决方案,并开始实现整个算法,然后配置文件,而不是修复性能问题。
但是,如果你觉得准备好了.常见的“重复”技术正在出现。您可以再创建一个顶点缓冲区(称为实例缓冲区),它将包含参数,而不是每个顶点,而是一个绘制实例的参数。然后用一个DrawInstanced()调用来完成所有的工作。
对于第一阶段,实例缓冲区可以包含D值和目标Texture3D层的索引。你可以从顶点着色器穿过它们。
与往常一样,您在这里有一个权衡:代码的简单性(可能是)性能。
2.多通道渲染
CPU需要参与将结果从临时纹理(V的结果)传递到第二次(H pass)。
通常,您会像这样进行链接,因此不涉及CPU:
// Pass 1: from pTexture0 to pTexture1
// ...set up pipeline state for Pass1 here...
pContext->PSSetShaderResources(slot, 1, pTexture0); // source
pContext->OMSetRenderTargets(1, pTexture1, 0); // target
pContext->Draw(...);
// Pass 2: from pTexture1 to pTexture2
// ...set up pipeline state for Pass1 here...
pContext->PSSetShaderResources(slot, 1, pTexture1); // previous target is now source
pContext->OMSetRenderTargets(1, pTexture2, 0);
pContext->Draw(...);
// Pass 3: ...注意,pTexture1必须同时具有D3D11_BIND_SHADER_RESOURCE和D3D11_BIND_RENDER_TARGET标志。您可以有多个输入纹理和多个渲染目标。只需确保,每次下一次传递都知道前面的pass输出。如果前面的pass使用了比当前更多的资源,不要忘记解除不必要的绑定,以防止难以找到的错误:
pContext->PSSetShaderResources(2, 1, 0);
pContext->PSSetShaderResources(3, 1, 0);
pContext->PSSetShaderResources(4, 1, 0);
// Only 0 and 1 texture slots will be used3.资源数据定位
所有的纹理是否一直驻留在GPU内存中,甚至在绘制()方法调用和像素/顶点着色器切换之间也是如此?
我们永远也不可能知道。驱动程序为资源选择适当的位置。但是,如果您有使用DEFAULT使用和0 CPU访问标志创建的资源,那么您几乎可以确定它总是在视频内存中。
希望能帮上忙。编码愉快!
https://stackoverflow.com/questions/18953768
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号