
基于支持向量机的人脸表情实时分类
我目前正在做一个项目,在这个项目中,我必须提取一个用户的面部表情(一次只能从一个网络摄像头中提取一个用户),比如悲伤或快乐。
我的面部表情分类方法是:
- 使用opencv检测图像中的人脸
- 用ASM和痉挛提取人脸特征点
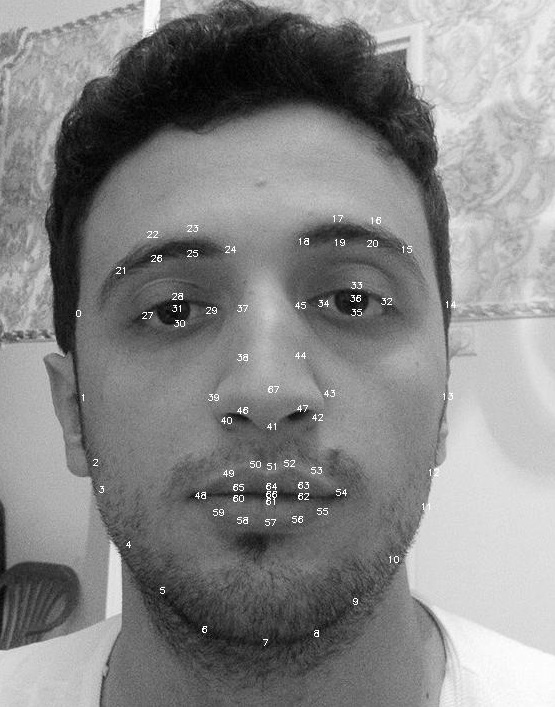
现在我试着做面部表情分类
支持向量机是一个不错的选择吗?如果是这样的话,我怎样才能从支持向量机开始:
我要怎么用这个地标来训练每个人的情绪?
回答 3
Stack Overflow用户
发布于 2013-09-05 17:18:33
是的,SVMs在这个任务中表现得很好。已经有几十份(如果不是上百份)文件描述了这些程序。
例如:
- 简单纸
- 长纸
- 关于它的海报
- 更复杂的例子
支持向量机本身的一些基本来源可以在http://www.support-vector-machines.org/上获得(如书籍标题、软件链接等)。
如果您只是对使用它们感兴趣,而不是理解它们,那么您可以获得一个基本库:
- libsvm http://www.csie.ntu.edu.tw/~cjlin/libsvm/
- svmlight http://svmlight.joachims.org/
Stack Overflow用户
发布于 2013-09-05 21:22:39
如果您已经在使用opencv,我建议您使用内置的svm实现,在python中进行培训/保存/加载如下。c++有相应的api来在相同数量的代码中执行相同的操作。它还有“train_auto”来寻找最佳参数
import numpy as np
import cv2
samples = np.array(np.random.random((4,5)), dtype = np.float32)
labels = np.array(np.random.randint(0,2,4), dtype = np.float32)
svm = cv2.SVM()
svmparams = dict( kernel_type = cv2.SVM_LINEAR,
svm_type = cv2.SVM_C_SVC,
C = 1 )
svm.train(samples, labels, params = svmparams)
testresult = np.float32( [svm.predict(s) for s in samples])
print samples
print labels
print testresult
svm.save('model.xml')
loaded=svm.load('model.xml')和输出
#print samples
[[ 0.24686454 0.07454421 0.90043277 0.37529686 0.34437731]
[ 0.41088378 0.79261768 0.46119651 0.50203663 0.64999193]
[ 0.11879266 0.6869216 0.4808321 0.6477254 0.16334397]
[ 0.02145131 0.51843268 0.74307418 0.90667248 0.07163303]]
#print labels
[ 0. 1. 1. 0.]
#print testresult
[ 0. 1. 1. 0.] 因此,你提供了n个扁平的形状模型作为样本和n个标签,你很适合去做。你可能甚至不需要asm部分,只需应用一些对方向敏感的过滤器,如sobel或gabor,将矩阵连接起来,然后将它们压平,然后直接将它们喂给svm。你可能会得到70%-90%的准确度。
就像有人说的,cnn是some的另一种选择,这里有一些实现lenet5的链接。到目前为止,我发现svm的启动要简单得多。
https://github.com/lisa-lab/DeepLearningTutorials/
http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi
-编辑-
地标只是n (x,y)向量,对吗?那么,你为什么不试着把它们放到一个2n大小的数组中,然后直接把它们喂给上面的代码呢?
例如,3个4个地标(0,0),(10,10),(50,50),(70,70)的训练样本
samples = [[0,0,10,10,50,50,70,70],
[0,0,10,10,50,50,70,70],
[0,0,10,10,50,50,70,70]]
labels=[0.,1.,2.]0=happy
1=angry
2=disgust
Stack Overflow用户
发布于 2013-09-08 15:53:35
您可以检查这代码,以了解如何使用支持向量机完成这一任务。
你可以找到算法解释这里
https://stackoverflow.com/questions/18640804
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号