
无法理解使用OCR引擎tesseract提取的文档中的坐标
无法理解使用OCR引擎tesseract提取的文档中的坐标
提问于 2013-08-31 16:38:06
我从tesseract中提取了一个图像文档,它提取成功。但我无法理解所提取的文件的坐标。
问题描述:-
它显示坐标,但让我知道,这些坐标代表像素或其他东西。这些都是像title="bbox 10 13 43 46",那么什么是10,13 43和46。他们代表的是什么立场
提取后的完整代码
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>
</title>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta name='ocr-system' content='tesseract'/>
</head>
<body>
<div class='ocr_page' id='page_1' title='image "D:\ABC.tif"; bbox 0 0 464 101'>
<div class='ocr_carea' id='block_1_1' title="bbox 10 13 330 55">
<p 1class='ocr_par'>
<span class='ocr_line' id='line_1_1' title="bbox 10 13 330 55">
<span class='ocr_word' id='word_1_1' title="bbox 10 13 43 46">
<span class='ocrx_word' id='xword_1_1' title="x_wconf -1"><strong>hi</strong></span>
</span>
<span class='ocr_word' id='word_1_2' title="bbox 148 13 268 47">
<span class='ocrx_word' id='xword_1_2' title="x_wconf -1"><strong>whats</strong></span>
</span>
<span class='ocr_word' id='word_1_3' title="bbox 283 22 330 55">
<span class='ocrx_word' id='xword_1_3' title="x_wconf -1"><strong>up</strong></span>
</span>
</span>
</p>
</div>
</div>
</body>
</html>回答 3
Stack Overflow用户
发布于 2016-02-18 15:40:28
对那些还在想坐标系统是如何工作的人来说,我终于找到了,这就像
10 13 43 46 startx,starty,endx,endy
如果你想找到这个单词的宽度和高度
宽度= endx - startx,高度= endy - starty
用‘’分隔字符串,然后消除bbox,就这样。
Stack Overflow用户
发布于 2018-03-14 17:16:33
也许这会对未来的人有所帮助。我认为这张照片本身就说明了问题。您可以计算高度或顶部距离(对于css)从这些值(例如。高度= y1-y0)
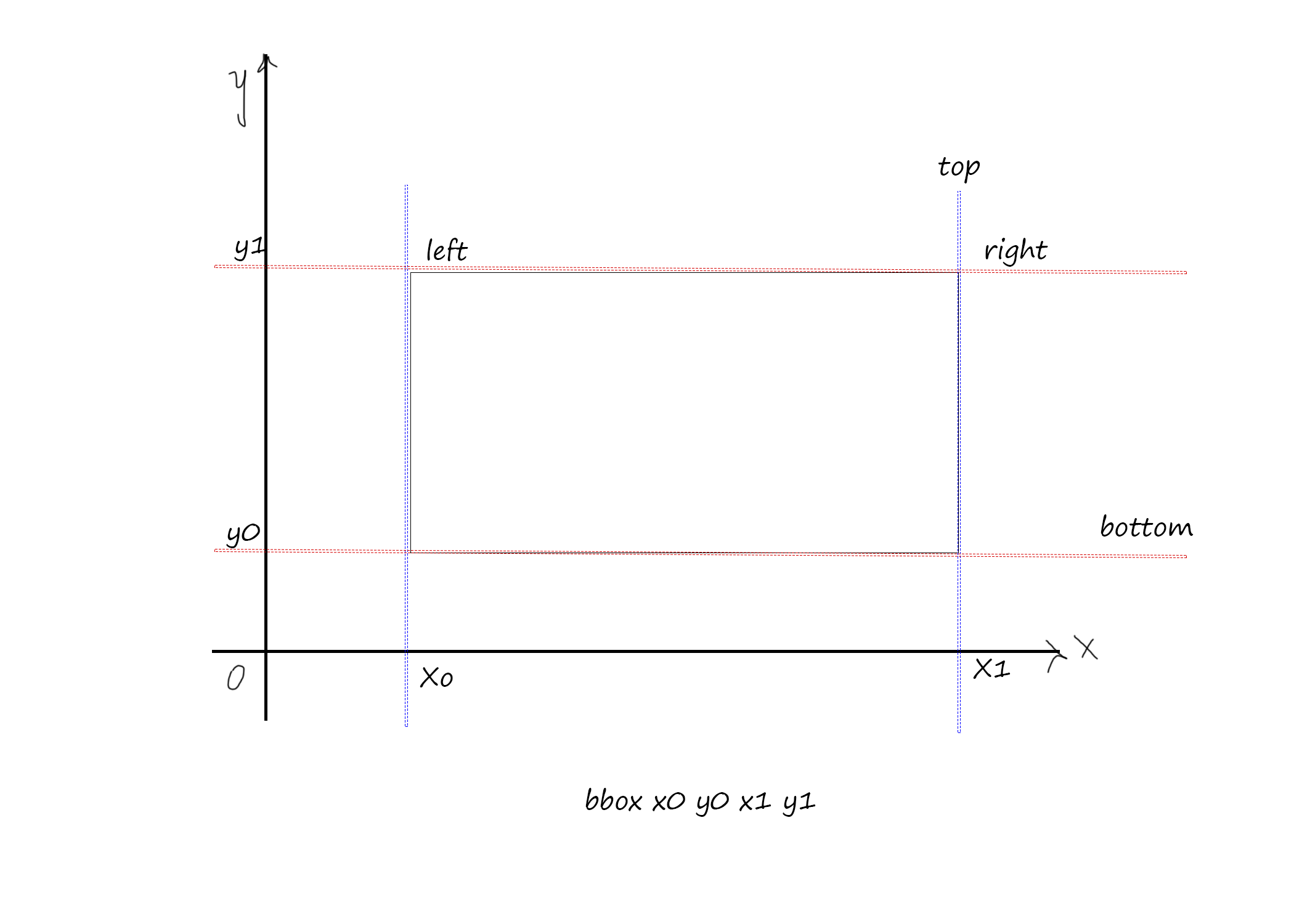
Stack Overflow用户
发布于 2013-08-31 17:18:10
这些数字应该显示一个方框(一个矩形)的角落的位置,在这里有一个单词。
这就是霍克尔协议。
根据您的文档,tesseract认得“嗨,你好”这句话
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/18550356
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号