
海量数据图形表示
我有一个大的data.frame (ncols = 500,nrow= 14000)。看起来是这样的:
Sample1 Sample2 Sample3 ..... Gene1 22 0 0.11 ..... Gene2 0.112 0.1 0.4 ..... Gene3 0.45 0 0.19 ..... ..... ..... ..... ..... .....
我想在不应用任何统计数据的情况下绘制如此庞大的数据,这样就可以清楚地(简单地使用颜色或其他工具)对ex的数字(大小)进行区分。在示例1的Gene1和Gene2之间,等等。除了热图之外还有其他的想法吗?
回答 2
Stack Overflow用户
发布于 2013-08-28 13:41:12
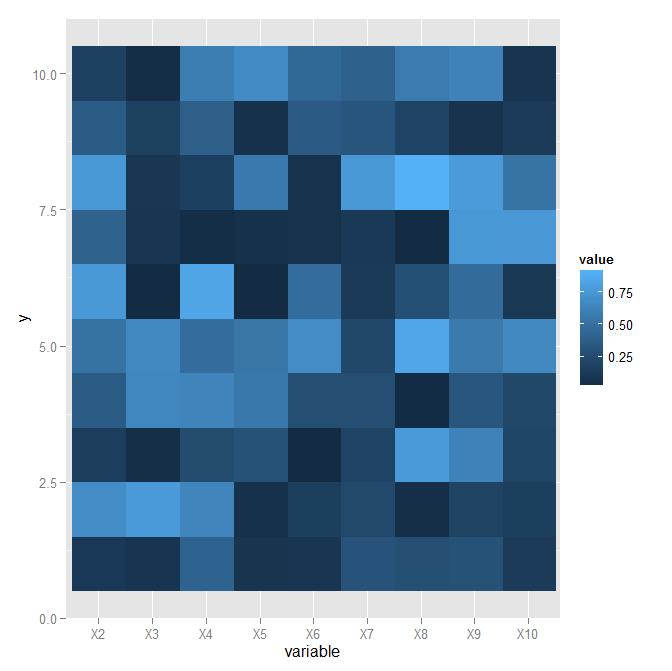
如何使用geom_raster从ggplot2?
# Make up some data
set.seed(1)
df <- data.frame( matrix( runif(25) , 5 , 5 ) )
# X1 X2 X3 X4 X5
#1 0.5316382 0.4360309 0.09576886 0.56497254 0.43930824
#2 0.2383700 0.1531009 0.71377161 0.39367645 0.42211072
#3 0.5009796 0.6549886 0.05996069 0.08236798 0.08574704
#4 0.1171437 0.8765644 0.29892712 0.06071803 0.78011966
#5 0.5066046 0.5486397 0.34770099 0.07785835 0.09659246
# Abs difference between columns of dataframe
out <- data.frame( t( apply( df , 1 , function(x) abs( diff( x ) ) ) ) )
# Plot using geom_raster
require( ggplot2 )
require( reshape2 )
out.melt <- melt( out )
out.melt$y <- rep( 1:10,times = 9 )
p <- ggplot( out.melt , aes( variable , y , fill = value ) ) + geom_raster()
p
Stack Overflow用户
发布于 2013-08-28 14:32:59
如果问题是关于真正巨大的数据(例如,当数据点的数量远大于屏幕上的像素数),那么Bin-概括-平滑:一个可视化大数据的框架,如这里所描述的,http://vita.had.co.nz/papers/bigvis.html怎么样?
@Article{bigvis,
title = {Bin-summarise-smooth: a framework for visualising large data},
author = {Hadley Wickham},
year = {Submitted},
journal = {Infovis 2013},
}也见(例如,本演示文稿的第5张幻灯片) R.pdf
https://stackoverflow.com/questions/18489146
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号