
我的洗牌功能有多随机?
我的洗牌功能有多随机?
提问于 2013-08-22 08:39:38
我正在编写一个心理学实验,我需要对每个参与者的刺激顺序进行调整。我有一个函数,随机排序我的刺激,然后我的程序从一个.txt文件中读取。在实验过程中(4500次试验),在样本中默认使用的伪随机算法(如我在下面的“洗牌”函数中所示)是否充分地洗牌,以实际地预期不会在任何刺激位置或刺激位置模式中产生任何系统的偏差?
stimulus <- c("a", "b", "c", "d", "e")
shuffle <- function (x) { as.data.frame(sample((t(x)))) }
shuffle (stimulus)回答 2
Stack Overflow用户
回答已采纳
发布于 2013-08-22 08:50:40
我会说是的,你可以画这个。如果它是真正的随机,我们会期望在每个位置的值在洗牌顺序的均匀分布,所以让我们重复多次实验,并绘制结果.
# Repeat experiment 10,000 times
res <- replicate( 10000 , shuffle(stimulus) )
out <- do.call( rbind , res )
# Plot
par( mfrow = c( 3 , 2 ) )
for( i in 1:ncol(out)){
hist( out[,i] , main = paste0("Values at position: " , i ) )
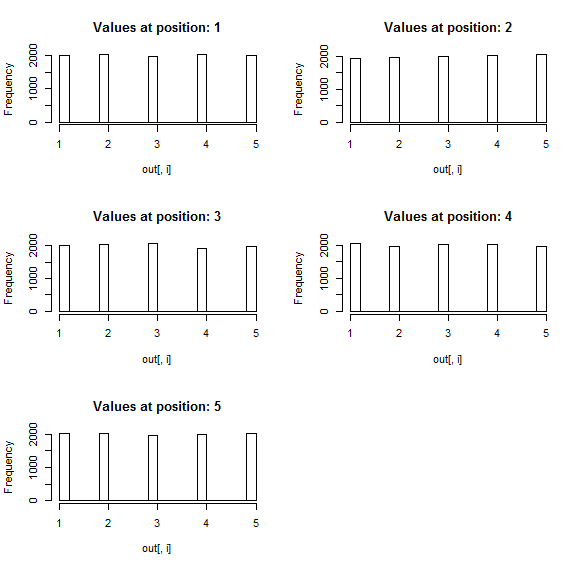
}每个直方图都是每个位置上值的分布。5个位置所以5个直方图。每个位置的可能值都是均匀分布的,所以我要说,您的值是以偶数概率(这是sample的缺省值)分配给每个位置的。
Stack Overflow用户
发布于 2013-08-22 08:45:13
R中的随机数发生器很好--该语言是针对统计学家的。几点。
- 有关使用的随机数生成器的详细信息,请参见
?RNG。 - 使用
set.seed使您的洗牌可复制 set.seed(1) - 您可以将代码简化为: 刺激= c("a","b","c","d","e") data.frame(sh=sample(刺激))
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/18375460
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号